一、LLM 介绍
1.1 LLM是什么?
LLM(Large Language Model, 大语言模型)是一种基于深度学习 Transformer 架构 的自然语言处理模型,通常拥有数十亿甚至上千亿的参数。这类模型通过大规模的数据训练,能够理解和生成自然语言文本,并可以在各种任务上表现出强大的能力。
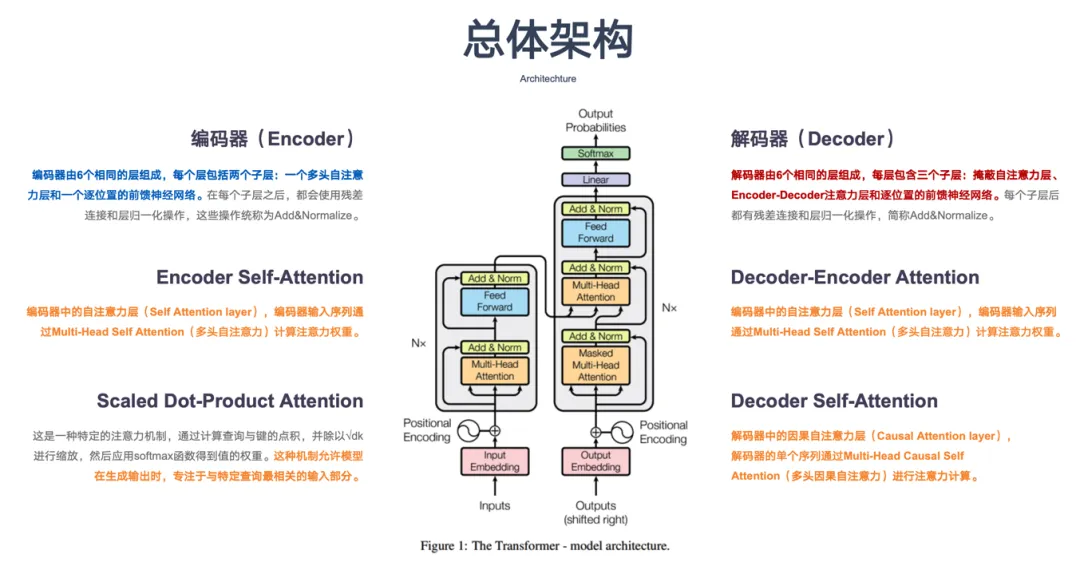
1.2 LLM 核心特点
==大规模参数==
LLM 的参数规模通常远大于传统 NLP 模型。参数量的增加让它能够捕捉到更多的语义细节和语言模式。
==自监督学习==
LLM 通过自监督学习(Self-supervised Learning)进行训练,不需要人工标注的数据。模型通过学习文本中的上下文关系来生成和理解语言。
==上下文感知==
LLM 能够理解上下文,生成与上下文相关的内容。通过多层 Transformer 结构捕捉文本的上下文关系,生成高质量的回答或续写。
==可迁移性==
训练后的 LLM 可以很好地迁移到不同领域的任务上,比如翻译、问答、摘要等,通过微调可以提高在特定任务或行业上的表现。
1.3 LLM如今为什么如此重要?
-
LLM 能够理解复杂的语言上下文,处理多种语言和不同语言风格,生成自然流畅的文字。这使得 LLM 成为各种文本生成任务的理想选择,比如文章创作、对话生成、客服问答等。相比以往的模型,LLM 能够生成更准确、连贯、富有逻辑的内容。
-
最新的 LLM 可以理解和使用语言,这在过去是无法企及的。基于此,为人类提供了一个强大的工具集和,增强了我们的创造力,并且提高了解决难题的效率。
1.4 LLM目前在生产环境面临的局限性
- 理解能力:大模型对输入非常敏感,一旦用户的描述不清晰或缺少关键信息,模型就可能给出跑偏甚至离题的答案
- 知识时效性问题:大语言模型在训练时只能使用某个时间点之前的数据,无法获得训练后发生的知识更新。
- 存储和计算效率:直接训练一个包含所有知识的大模型成本高昂,不仅需要巨大的存储空间,还需要强大的计算资源。
- 上下文局限性:大模型通常有最大输入长度的限制,无法处理特别长的上下文或长文档。
- 知识准确性(幻觉):由于生成模型在推理时基于概率分布,它们可能会生成模棱两可或不准确的内容,特别是在回答一些冷门知识或专业领域的问题时。
- 知识覆盖范围:模型训练中难以覆盖所有细分领域的知识,尤其是一些长尾内容。
- 数据安全性:对于企业来说,数据安全至关重要,没有企业愿意承担数据泄露的风险,将自身的私域数据上传第三方平台进行训练。
- 无法自主执行复杂任务:大模型无法主动执行外部操作,只能依靠对话的方式给出静态答案,对于需要多步操作、调用外部API、或访问特定系统的信息时就束手无策
正是基于以上的局限性,我们需要在生产环境配合一系列的工程手段,将LLM 和自身的业务能够相融相合。
二、LLM应用技术
因为大模型上述的这些局限性,在生产环境的实践中,我们逐渐探索出 提示词工程(Prompt Engineering)、**RAG(Retrieval-Augmented Generation)**和 Agent 等技术来弥补这些短板。
- Prompt Engineering 能让大模型在回答前对需求有更精确的理解,降低“跑题”或“幻觉”等问题;
- RAG 会在模型生成答案前检索外部知识库,以提供最新或更专业的参考信息,让模型有更广、更实时的知识背景;
- Agent 则赋予模型自主决策和调用外部系统的能力,使之不仅能给出文本回答,还可以执行更复杂的任务流程;
这三者结合能大幅度提高大模型在实际业务场景中的应用效果。
==三项技术具体如何解决大模型的局限性==
| 局限性 | 解决方法 |
|---|---|
| 理解能力 | Prompt Engineering 通过精心设计 Prompt,把问题背景、期望答案形式和必要的思维路径都明确告诉模型,能够让大模型聚焦在真正需要回答的内容上,从而减少理解偏差,提升回答的准确度与可控性。 |
| 知识时效性问题 | RAG 通过实时检索外部数据库中的信息,可以帮助模型获得训练之后更新的数据,克服了大模型知识“过时”的问题。 |
| 存储和计算效率 | 与直接将所有知识嵌入模型参数中不同,RAG 通过检索实现按需调用知识,降低了对模型参数规模的需求,从而减小模型的计算和存储开销。 |
| 上下文局限性 | RAG 的检索模块可以从长文档中提取关键内容,再传递给生成模块,从而有效解决输入长度的限制问题。 |
| 知识准确性(幻觉) | RAG 可以在知识库中找到与问题相关的具体内容,使生成的回答更加专业和准确。 |
| 知识覆盖范围 | RAG 可以在知识库中找到与问题相关的具体内容,使生成的回答更加专业和准确。 |
| 数据安全性 | RAG 将模型训练数据与检索数据分离,一定程度上保证数据的安全性 |
| 无法自主执行复杂任务 | Agent 赋予模型自主决策和调用外部系统的能力,使之不仅能给出文本回答,还可以执行更复杂的任务流程 |
接下来,我们将详细介绍这三项技术。
2.1 提示工程(Prompt Engineering)——大模型应用技术的基础
提示工程,也称为上下文提示,是指通过改变LLM以引导其行为以获得期望的结果,而无需更新模型权重的方法。这是一门经验科学,提示工程方法的效果在各种模型之间可能会有很大差异,因此需要进行大量实验和启发式方法。
2.1.1 大模型提示的重要性
==Prompt(提示)—— AGI时代的“编程语言”==
在人工智能,尤其是 AGI(Artificial General Intelligence)时代,Prompt(提示)正扮演着至关重要的角色。它不仅是用户与 AI 模型交互的桥梁,更是一种全新的“编程语言”,用于指导 AI 模型生成特定的输出。
-
角色转变 过去,Prompt 只被视为简单的输入或查询;如今,它已演变为一种与 AI 模型互动的“编程语言”。通过精心设计的 Prompt,用户可以“编程”AI 模型,指导其执行各式各样的任务。
-
任务多样性 这些任务覆盖范围极广,从简单的问答、文本生成,到复杂的逻辑推理、数学计算以及富有创意的写作等,几乎涵盖了各种可能的应用场景。
-
即时性与互动性 与传统的编程语言相比,Prompt 更加注重即时性和互动性。用户只需在 AI 模型的接口中输入 Prompt,便能立即获得反馈,无需经历编译或长时间运行的过程。
这种新型的“Prompt 编程”不仅改变了人机交互方式,也为各行各业的创新和效率提升带来了无限可能。

2.1.2 提示工程是什么?
==提示工程(Prompt Engineering)—— AGI时代的“软件工程”==
在 AGI(Artificial General Intelligence)时代,提示工程(Prompt Engineering)是一门围绕 Prompt(提示)的全新“软件工程”实践。它涵盖如何设计、优化和管理这些 Prompt,以确保 AI 模型能够准确、高效地执行用户指令。
-
**设计(Design)**在设计 Prompt 时,需要细心推敲词汇选择,并构造清晰的句子结构,同时充分考虑上下文信息。这些努力有助于 AI 模型准确理解用户意图,从而输出更符合预期的结果。
-
**优化(Optimization)**为了让 AI 模型表现得更好,常需要不断调整 Prompt。例如,改进词汇选择、完善句子结构,或补充额外的上下文信息,都可能显著提升 AI 模型的性能和准确率。通常需要经过多次尝试和迭代,才能找到最佳的 Prompt 方案。
-
**管理(Management)**随着 AGI 应用规模的扩大与复杂度的提升,Prompt 的数量与种类也会相应增加。对这些 Prompt 进行有效的组织、存储和检索,能够在需要时快速调用并重复使用。此外,Prompt 也需定期更新与维护,以适应 AI 模型的持续迭代与新需求的出现。
通过引入专业的提示工程方法论,我们可以更高效、更准确地驱动 AI 模型完成各种任务,为 AGI 时代的创新与实践奠定更坚实的基础。
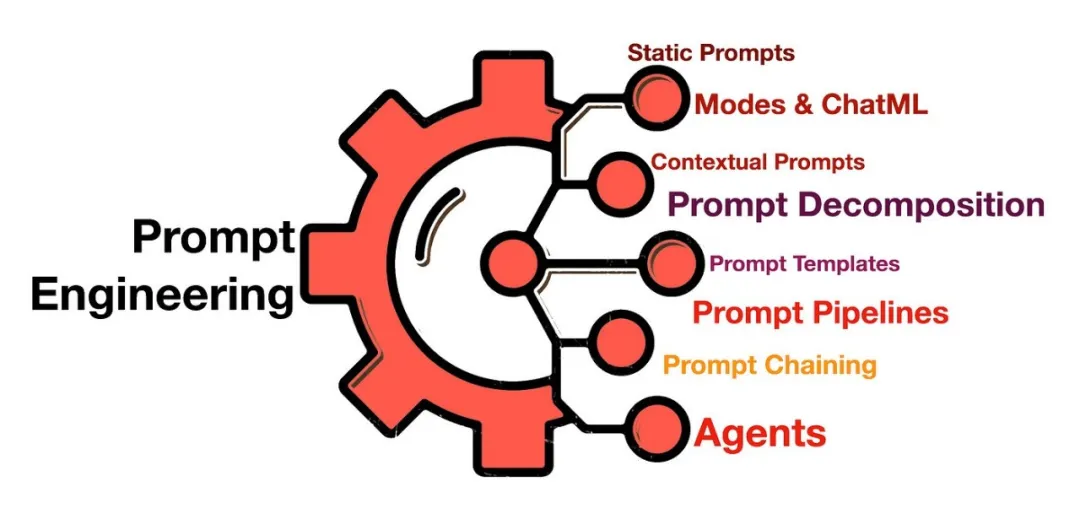
2.1.3 怎么做提示工程?
==Prompt的构成==
一个完整的Prompt应该包含清晰的指示、相关的上下文、有助于理解的例子、明确的输入以及期望的输出格式描述。
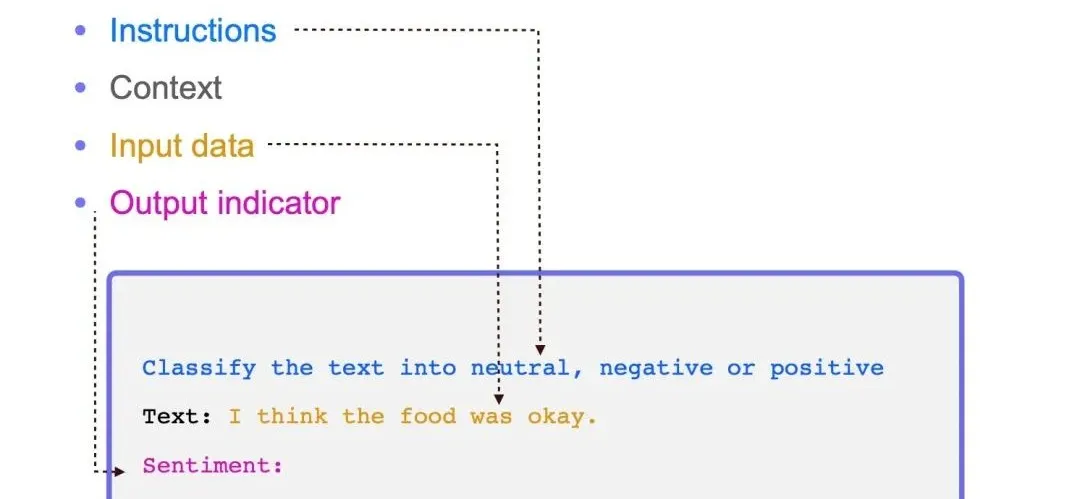
指示(Instructions) - 任务描述
指示是对任务的明确描述,相当于给模型下达了一个命令或请求。它告诉模型应该做什么,是任务执行的基础。
上下文(Context) - 背景信息
上下文是与任务相关的背景信息,它有助于模型更好地理解当前任务所处的环境或情境。在多轮交互中,上下文尤其重要,因为它提供了对话的连贯性和历史信息。
例子(Examples) - 示范学习
例子是给出的一或多个具体示例,用于演示任务的执行方式或所需输出的格式。这种方法在机器学习中被称为示范学习,已被证明对提高输出正确性有帮助。
输入(Input) - 数据输入
输入是任务的具体数据或信息,它是模型需要处理的内容。在Prompt中,输入应该被清晰地标识出来,以便模型能够准确地识别和处理。
输出(Output) - 结果格式
输出是模型根据输入和指示生成的结果。在Prompt中,通常会描述输出的格式,以便后续模块能够自动解析模型的输出结果。常见的输出格式包括结构化数据格式如JSON、XML等。
==Prompt调优==
Prompt调优是人与机器协同的过程,需明确需求、注重细节、灵活应用技巧,以实现最佳交互效果。
人的视角:明确需求
- 核心点:确保清晰、具体地传达意图。
- 策略:把复杂需求拆解成模型易于理解和处理的指令,做到条理清晰、逻辑分明。
机器的视角:注重细节
- 核心点:机器缺乏人类直觉,因此必须详细提供信息和上下文。
- 策略:精准选择词汇和句子结构,避免歧义,并在适当的地方补充完整线索,为模型提供足够的信息基础。
模型的视角:灵活应用技巧
- 核心点:面对不同的模型与应用场景,应采用不同的 Prompt 表达方式。
- 策略:通过不断实践与测试,寻找最佳的词汇、结构和技巧,适应各类模型的特性,持续优化交互效果。
2.1.4 提示工程的应用实践
2.1.4.1 零样本提示(Zero-Shot Prompting)
零样本提示就是简单地将任务文本输入模型并要求结果。
Prompt:
将文本分类为中性、负面或正面。
文本:我认为这次假期还可以。
情感:
Output:
中性
2.1.4.2 少样本提示(Few-Shot Prompting)
Few-shot 提示提供一组高质量的演示,每个演示均包括目标任务上的输入和期望输出。模型首先看到好的示例,能更好地理解人类意图和想要的答案类型。
因此,Few-shot 提示通常比 Zero-shot 提示表现更好。然而,这是以更多 token 消耗为代价的,当输入和输出文本较长时可能会达到上下文长度限制。
Prompt:
“whatpu”是坦桑尼亚的一种小型毛茸茸的动物。一个使用whatpu这个词的句子的例子是:
我们在非洲旅行时看到了这些非常可爱的whatpus。
“farduddle”是指快速跳上跳下。一个使用farduddle这个词的句子的例子是:
Output:
当我们赢得比赛时,我们都开始庆祝farduddle。
2.1.4.3 思维链提示(Chain-of-Thought Prompting)
Chain-of-Thought Prompting,即链式思考提示,是一种在人工智能模型中引导逐步推理的方法。通过构建一系列有序、相互关联的思考步骤,模型能够更深入地理解问题,并生成结构化、逻辑清晰的回答。
==核心特点==
- 有序性:链式思考提示要求将问题分解为一系列有序的步骤,每个步骤都建立在前一个步骤的基础上,形成一条清晰的思考链条。
- 关联性:每个思考步骤之间必须存在紧密的逻辑联系,以确保整个思考过程的连贯性和一致性。
- 逐步推理:模型在每个步骤中只关注当前的问题和相关信息,通过逐步推理的方式逐步逼近最终答案。
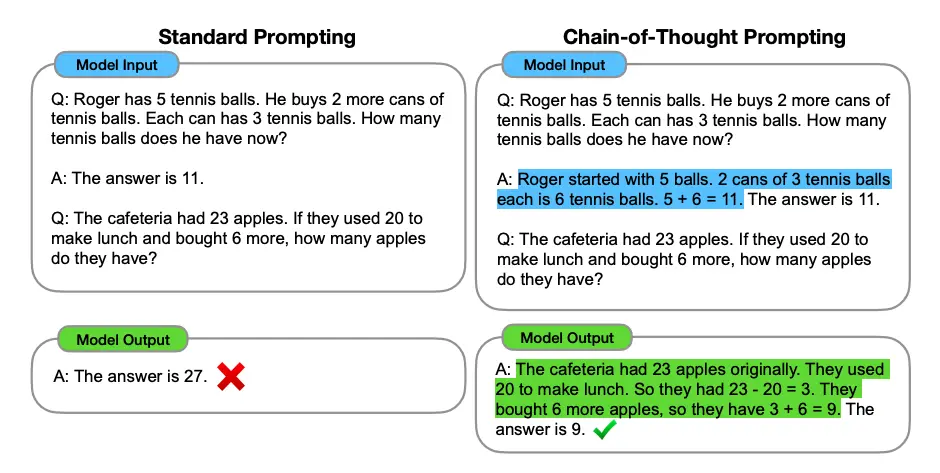
Prompt:
这组数中的奇数加起来是偶数:4、8、9、15、12、2、1。
A:将所有奇数相加(9、15、1)得到25。答案为False。
这组数中的奇数加起来是偶数:17、10、19、4、8、12、24。
A:将所有奇数相加(17、19)得到36。答案为True。
这组数中的奇数加起来是偶数:16、11、14、4、8、13、24。
A:将所有奇数相加(11、13)得到24。答案为True。
这组数中的奇数加起来是偶数:17、9、10、12、13、4、2。
A:将所有奇数相加(17、9、13)得到39。答案为False。
这组数中的奇数加起来是偶数:15、32、5、13、82、7、1。
A:
Output:
将所有奇数相加(15、5、13、7、1)得到41。答案为False。
2.1.4.4 生成知识提示(Knowledge Generation Prompting)
Knowledge Generation Prompting,即生成知识提示,是一种利用人工智能模型生成新知识或信息的方法。通过构建特定的提示语句,引导模型从已有的知识库中提取、整合并生成新的、有用的知识内容。
==核心特点==
- 创新性:生成知识提示旨在产生新的、原创性的知识内容,而非简单地复述或重组已有信息。
- 引导性:通过精心设计的提示语句,模型被引导去探索、发现并与已有知识进行交互,从而生成新的见解或信息。
- 知识整合:该过程涉及对多个来源、多种类型的知识进行融合和整合,以形成更全面、深入的理解。
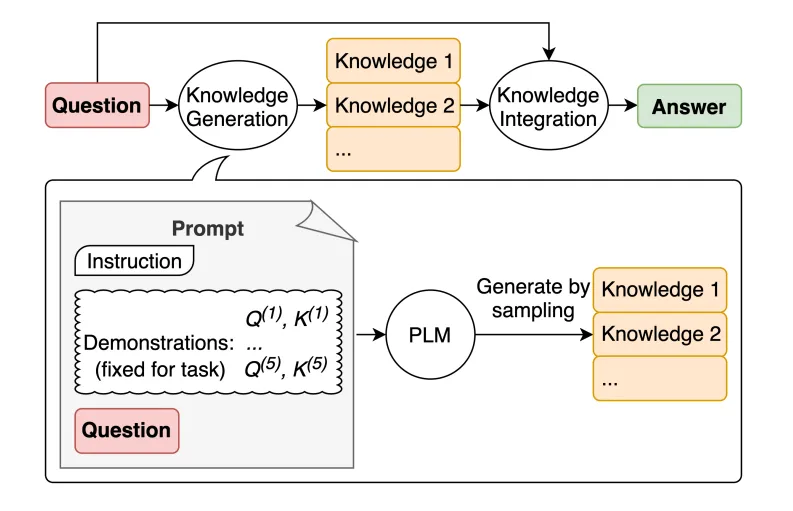
==举例==
原始提示
Prompt:
高尔夫球的目标是试图获得比其他人更高的得分。是或否?
Output:
是。
生成知识提示
- 生成知识
Prompt:
输入:希腊比墨西哥大。
知识:希腊的面积约为131,957平方公里,而墨西哥的面积约为1,964,375平方公里,使墨西哥比希腊大了1,389%。
输入:眼镜总是会起雾。
知识:当你的汗水、呼吸和周围的湿度中的水蒸气落在冷的表面上,冷却并变成微小的液滴时,会在眼镜镜片上产生冷凝。你看到的是一层薄膜。你的镜片相对于你的呼吸会比较凉,尤其是当外面的空气很冷时。
输入:鱼有思考能力。
知识:鱼比它们看起来更聪明。在许多领域,如记忆力,它们的认知能力与或超过非人类灵长类动物等“更高级”的脊椎动物。鱼的长期记忆帮助它们跟踪复杂的社交关系。
输入:一个人一生中吸烟很多香烟的常见影响是患肺癌的几率高于正常水平。
知识:那些一生中平均每天吸烟不到一支香烟的人,患肺癌的风险是从不吸烟者的9倍。在每天吸烟1到10支香烟之间的人群中,死于肺癌的风险几乎是从不吸烟者的12倍。
输入:一块石头和一颗卵石大小相同。
知识:卵石是一种根据Udden-Wentworth沉积学尺度的颗粒大小为4到64毫米的岩屑。卵石通常被认为比颗粒(直径2到4毫米)大,比卵石(直径64到256毫米)小。
输入:高尔夫球的一部分是试图获得比其他人更高的得分。
知识:
Output:
高尔夫球的目标是以最少的杆数打完一组洞。一轮高尔夫球比赛通常包括18个洞。每个洞在标准高尔夫球场上一轮只打一次。每个杆计为一分,总杆数用于确定比赛的获胜者。
- 进行提问
Prompt:
问题:高尔夫球的一部分是试图获得比其他人更高的得分。是或否?
知识:高尔夫球的目标是以最少的杆数打完一组洞。一轮高尔夫球比赛通常包括18个洞。每个洞在标准高尔夫球场上一轮只打一次。每个杆计为一分,总杆数用于确定比赛的获胜者。
解释和答案:
Output:
不是,高尔夫球的目标不是获得比其他人更高的得分。相反,目标是以最少的杆数打完一组洞。总杆数用于确定比赛的获胜者,而不是总得分。
2.1.4.5 思维树提示(Tree of Thoughts Prompting)
Tree of Thoughts Prompting,即思维树提示,是一种将复杂思维过程结构化为树状图的方法。它通过逐级分解主题或问题,形成具有逻辑层次和关联性的思维节点,从而帮助用户更清晰地组织和表达思考过程。
==核心特点==
- 层次性:思维树提示将思考过程分解为多个层次,每个层次代表不同的思维深度和广度。
- 关联性:各思维节点之间存在紧密的逻辑联系,形成一个相互关联、互为支撑的思维网络。
- 可视化:通过将思维过程以树状图的形式展现,思维树提示增强了思考过程的可视化和直观性。
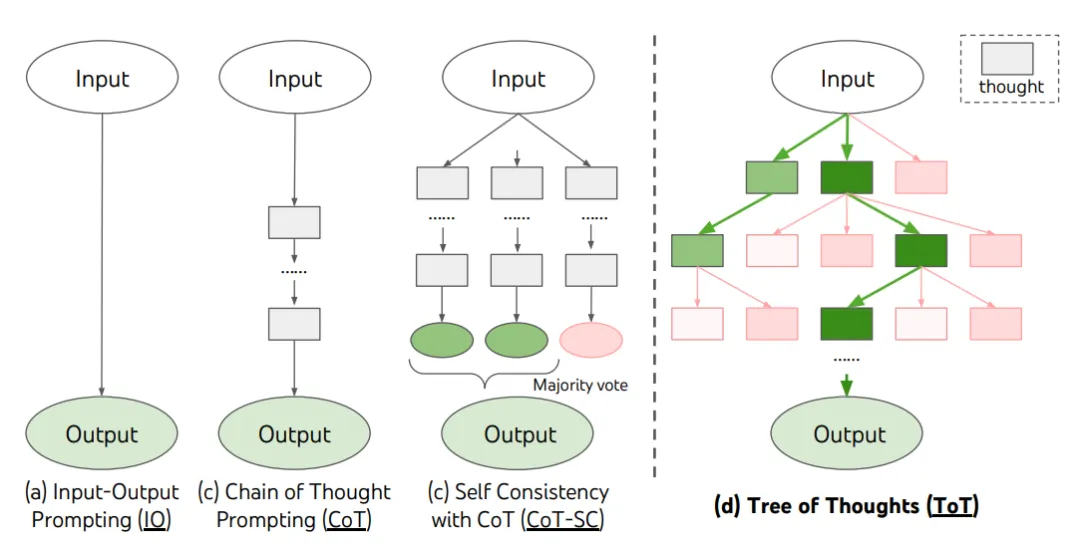
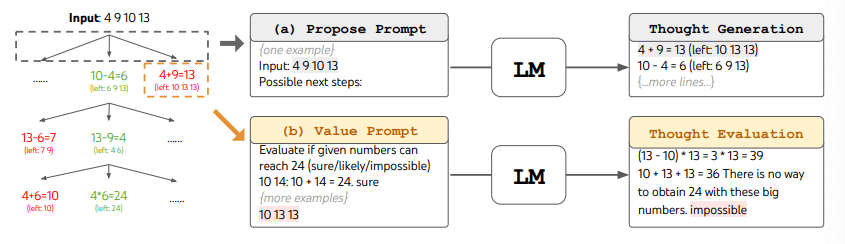
多轮对话方式举例:
“算 24 游戏”是一种数学推理任务,需要分成 3 个思维步骤,每一步都需要一个中间方程。而每个步骤保留最优的(best) 5 个候选项。
ToT 完成算 24 的游戏任务要执行广度优先搜索(BFS),每步思维的候选项都要求 LM 给出能否得到 24 的评估:“sure/maybe/impossible”(一定能/可能/不可能) 。“目的是得到经过少量向前尝试就可以验证正确(sure)的局部解,基于‘太大/太小’的常识消除那些不可能(impossible)的局部解,其余的局部解作为‘maybe’保留。”每步思维都要抽样得到 3 个评估结果。整个过程如下图所示:
一个Prompt方式举例:
假设三位不同的专家来回答这个问题。
所有专家都写下他们思考这个问题的第一个步骤,然后与大家分享。
然后,所有专家都写下他们思考的下一个步骤并分享。
以此类推,直到所有专家写完他们思考的所有步骤。
只要大家发现有专家的步骤出错了,就让这位专家离开。
请问...
2.2 检索增强生成(RAG)——部分解决大模型的局限性
2.2.1 向量 Vector & Embeddings
2.2.1.1 什么是向量?
在数学和计算机领域,向量有着不同的含义
==数学概念——Vector(向量)==
- 数学上的通用概念,是一个有方向和大小的实体,可以在几何空间中表示,也可以是一个 n 维的数值序列。
- 形式:向量通常如下图所示 ,可以表示几何点、物理量(如速度、力)或者任意数据序列。
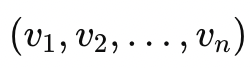
- 应用广泛,例如物理(速度、加速度等)和数学计算。
==计算机概念——Embeddings(嵌入)==
- 是一个特定领域的概念,指的是将高维或复杂结构的数据映射到低维向量空间中,同时尽可能保留数据的原始特征或语义关系。
- 常用于自然语言处理(NLP)和机器学习领域,将文本、图像或其他高维对象表示为向量,便于计算和分析。
- 通常通过机器学习模型训练得到。
- 举例:为了描述人,我们可以通过
[身高,体重,性别]来提取一个人特征
注:一般描述一个 embeddings 时,我们要明白他代表的是一个数据的特征,当我们作图表示这个 embeddings 时,一般采用数学上的定义,定义为有方向和大小的实体,而且一般是用 2 维或者 3 维来表示,尽管这个embeddings 可能是 768 维的,因为人无法想象超过 3 维的概念。
==向量:AI 时代的数据交换“新标准”==
随着 AI 技术的不断发展,向量正在逐步崭露头角,成为 AI 时代潜在的“数据交换标准”,就像互联网时代广泛使用的 JSON(JavaScript Object Notation)一样。
- 数据表示在 AI 领域,各种类型的数据(包括文本、图像、声音等)常被转换成向量形式,以便后续的处理和分析。
- 特征提取向量中的每个元素通常代表数据的一项特征。例如在图像中可对应像素强度,在文本中可对应语义属性。
- 模型参数在机器学习过程中,模型的参数(如权重、偏差)多以向量形式表示,并通过各种优化算法来进行迭代训练。
- 有序性向量中的元素以固定顺序排列,每个位置对应一个特定维度,保证了数据结构的有序性。
- 可运算性向量可以进行加法、减法、点积等数学运算,这些运算在 AI 算法中被广泛应用,便于快速处理和计算。
- 多维度向量的维度(即元素数量)可根据具体任务和数据类型而变化,可能是二维、三维,也可能是数百乃至数千维度。
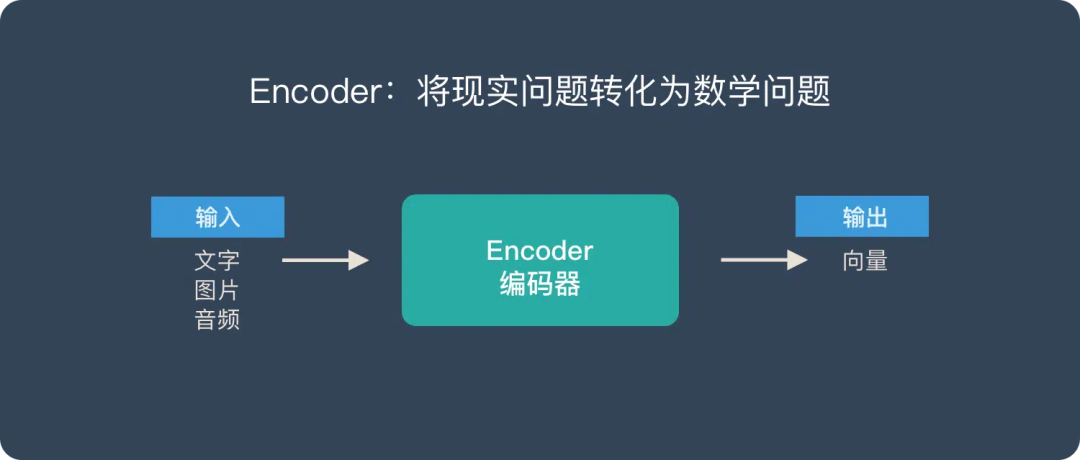
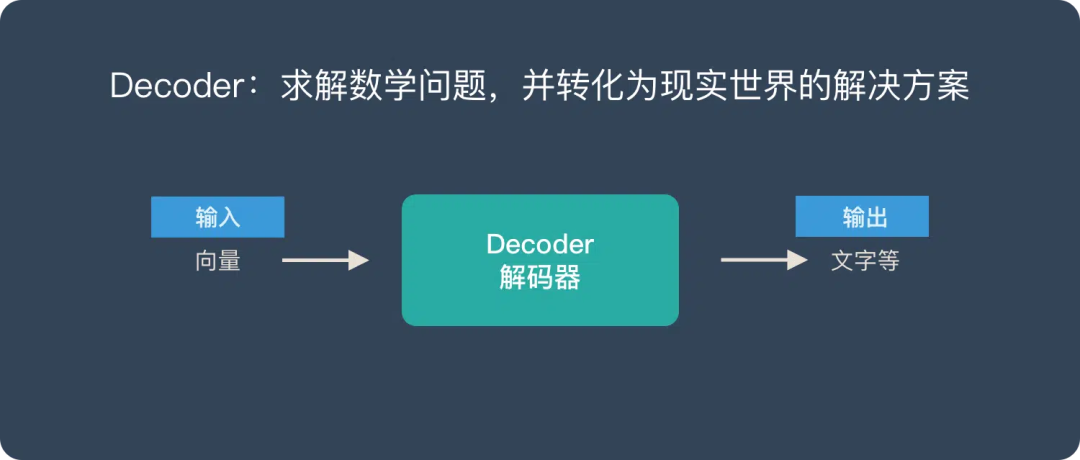
==向量是Encoder-Decoder的桥梁:将现实问题转化为数学问题,通过求解数学问题来得到现实世界的解决方案。==
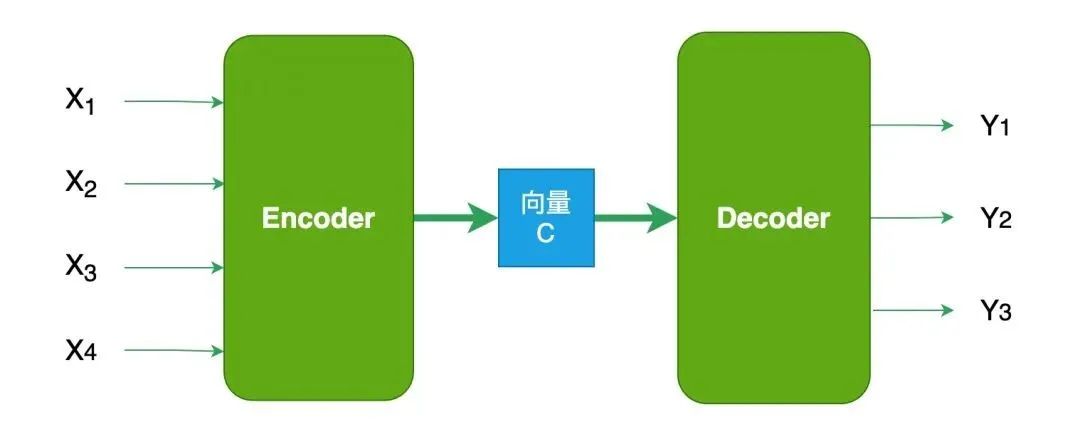
- Encoder (编码器) “将现实问题转化为数学问题”
- Decoder (解码器) “求解数学问题,并转化为现实世界的解决方案”
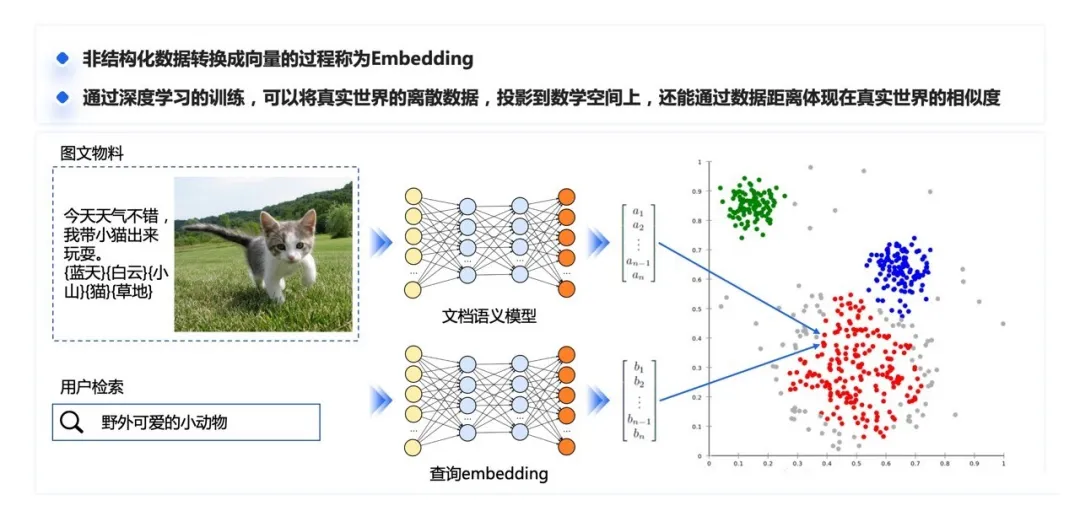
2.2.1.2 向量转换过程(Embedding)
非结构化数据转换成向量的过程称为 Embedding(嵌入)。通过深度学习的训练,可以将真实世界数字化后的离散特征提取出来,投影到数学空间上,成为一个数学意义上的向量,同时很神奇的保留着通过向量之间的距离表示语义相似度的能力。

文本向量化(Text Embedding)
将文本数据(词、句子、文档)表示成向量的方法。
词向量化
将单个词转换为数值向量
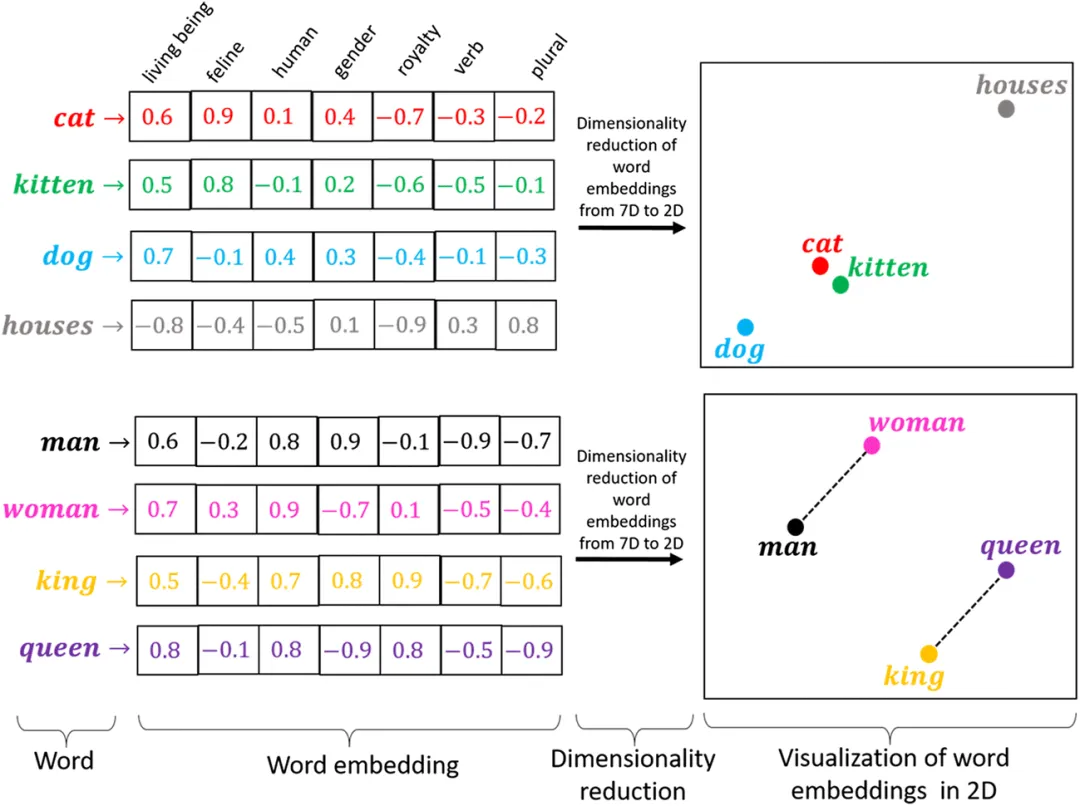
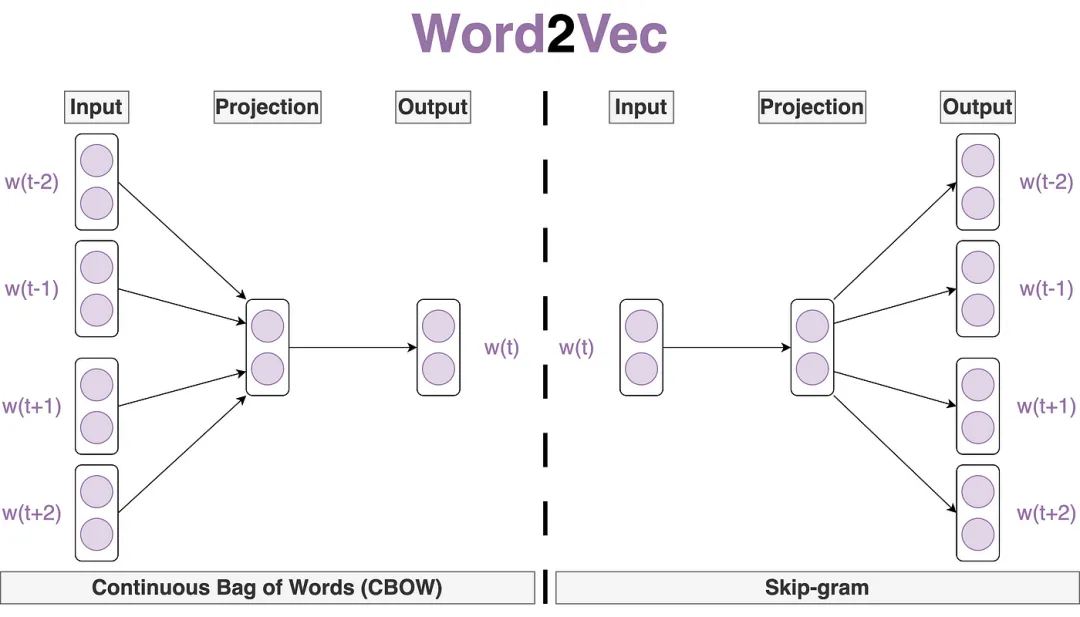
Word2Vec:一种捕捉单词语义与语法关系的词向量化技术
Word2Vec 是一项广为人知的 Word Embedding(词向量化)技术,用于将单词表示为高维空间中的密集向量,从而捕捉单词之间的语义和语法关系。它主要包括以下两种模型:
-
Skip-Gram(跳字模型)
-
核心思路:通过给定的“中心词”来预测其上下文中的单词。
-
工作方式:对于文本中的每个单词,Skip-Gram 模型将其视作中心词,并尝试预测一定窗口大小内出现的其他单词(即上下文单词)。
-
形象比喻:好比一个“词汇侦探”,利用中心词这一“线索”,去“追踪”并预测周围的单词,从而构建词汇间的语义关联。
-
-
CBOW(Continuous Bag of Words,连续词袋模型)
-
核心思路:与 Skip-Gram 相反,CBOW 模型通过给定的“上下文单词”来预测中心词。
-
工作方式:对于文本中的每个中心词,CBOW 模型会将其周围一定窗口大小内的其他单词(即上下文单词)作为输入,并尝试预测该中心词。
-
特点:通过聚合周围词的信息,逆向推断中心词的特征,实现词向量的学习。
-
这两种模型各有侧重,Skip-Gram 更适用于语料规模较大、关注低频词的情况,而 CBOW 在处理速度和计算效率方面更具优势。通过 Word2Vec,我们不仅能获取单词之间更丰富、更细致的语义关系,也能为后续的自然语言处理任务(如文本分类、情感分析等)提供更有力的支持。
句子向量化
将整句话转换为一个数值向量。相比仅对单词进行向量化,句子向量化能够更全面地表示句子的整体语义和语法信息,因而在语义搜索、情感分析、机器翻译等任务中都至关重要。常见的方法包括:
- 简单平均/加权平均
- 做法:对句子中每个单词的词向量进行平均,或根据单词频率进行加权平均。
- 特点:实现简单、计算量小,但无法充分捕捉单词在句子中的顺序和相互依赖关系。
- 递归神经网络(RNN)
- 做法:通过循环或递归地处理句子中的每个词,将前面词的表示与当前词进行合并,逐步生成句子表示。
- 优点:适合处理序列数据,能在一定程度上捕捉上下文依赖。
- 示例:LSTM、GRU 等变体在长句子或复杂依赖关系的表征上有更好的效果。
- 卷积神经网络(CNN)
- 做法:利用卷积层对句子进行局部特征提取,随后经过池化等操作得到整体句子表示。
- 优点:在提取局部特征、识别关键信息方面表现较好,同时具有并行计算的优势。
- 适用场景:常用于句子分类、文本情感分析等任务。
- 自注意力机制(如 Transformer)
- 做法:典型代表是 BERT、GPT 系列等模型,通过自注意力机制对句子中每个词与其他词的关系进行加权计算,从而生成包含全局信息的句子表示。
- 优点:擅长捕捉长距离依赖,平行化效果好,已成为当前自然语言处理中的主流方法。
文档向量化
将整个文档(如一篇文章或一组句子)转换为一个数值向量。
- 简单平均/加权平均:对文档中的句子向量进行平均或加权平均。
- 层次化模型:如Doc2Vec,它扩展了Word2Vec,可以生成整个文档的向量表
图像向量化(Image Embedding)
将图像数据转换为向量的过程。卷积神经网络和自编码器都是用于图像向量化的有效工具,前者通过训练提取图像特征并转换为向量,后者则学习图像的压缩编码以生成低维向量表示。
卷积神经网络(CNN)
- 通过训练卷积神经网络模型,我们可以从原始图像数据中提取特征,并将其表示为向量。例如,使用预训练的模型(如VGG16, ResNet)的特定层作为特征提取器。
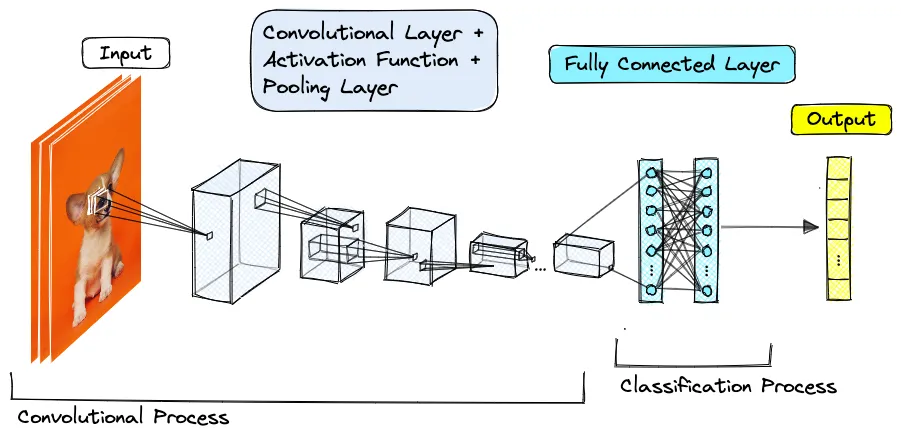
自编码器(Autoencoders)
这是一种无监督的神经网络,用于学习输入数据的有效编码。在图像向量化中,自编码器可以学习从图像到低维向量的映射。

视频向量化(Vedio Embedding)
视觉块的引入
为了将视觉数据转换成适合生成模型处理的格式,研究者提出了视觉块嵌入编码(visual patches)的概念。这些视觉块是图像或视频的小部分,类似于文本中的词元。
处理高维数据
在处理高维视觉数据时(如视频),首先将其压缩到一个低维潜在空间。这样做可以减少数据的复杂性,同时保留足够的信息供模型学习。

使用patches,可以对视频、音频、文字进行统一的向量化表示**,和大模型中的 tokens 类似**
2.2.1.3 向量距离计算方式
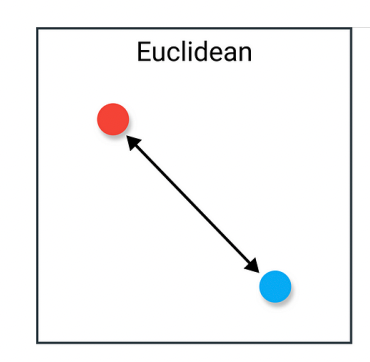
==Euclidean Distance(欧几里得距离)(L2)==
几何距离
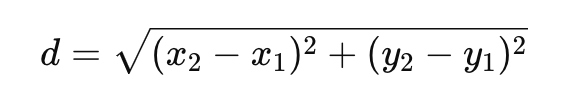
- 欧几里得距离是最常见、最直观的“几何距离”衡量方法。
- 广泛应用于聚类 (Clustering)、kNN (k-Nearest Neighbors) 等场景,尤其在数值型、连续型数据上使用频率非常高。
- 在低维度空间里直观且易于理解,但在高维度空间里往往会遇到“维度灾难”问题,欧几里得距离的分辨力可能会下降。
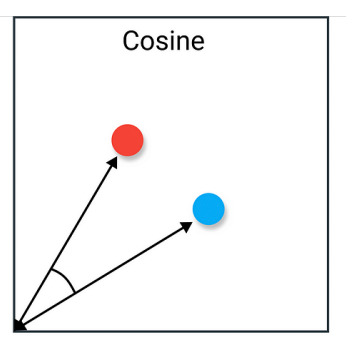
==Cosine Distance(余弦距离/相似度)==
余弦相似度(Cosine Similarity)测量的是两个向量夹角的相似度,可用下面的公式表示:
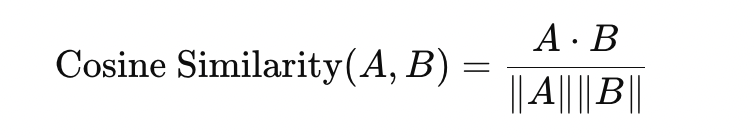
- 适合用来比较方向而非绝对大小的相似度,在文本向量化、推荐系统、自然语言处理等场景被大量使用。
- 当我们关心的是不同向量之间的“相似角度”而不太关注向量的具体长度时,余弦相似度/距离会更有效。
- 常用于高维稀疏向量(比如文本词频向量)场景。
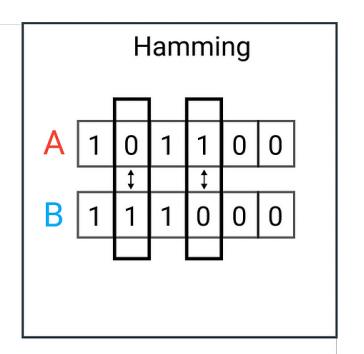
==Hamming Distance(汉明距离)==
在两个等长的序列(通常是二进制串)之间,对应位置不同的个数就是它们的汉明距离。例如:A=101100,B=111000对应位置不同的共有 2 个,所以
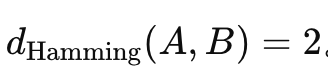
- 主要用于离散型数据(如二进制、字符串、编码数据)的差异度计算。
- 在纠错码 (Error-correcting codes)、信息传输和存储领域(比如 CRC、校验位)中至关重要。
- 用于比较两个 DNA 序列时出现多少个碱基不一样,也可用汉明距离来衡量。
==Manhattan Distance(曼哈顿距离)(L1)==
又称 L1 距离,指在各维度上取绝对差值再相加,例如二维空间中:
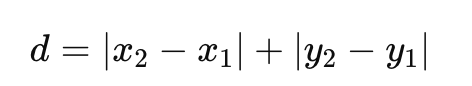
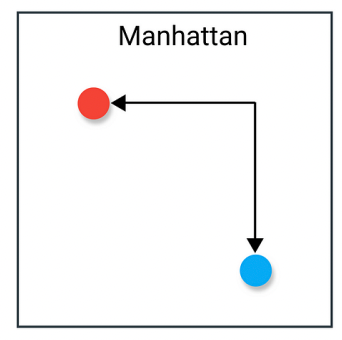
这好像在“城市街道”中行走,每次只能走水平或垂直方向。
- 当特征是绝对值差的累积更有意义时,可选曼哈顿距离。
- 在一些稀疏模型中(如 L1 正则)会与曼哈顿距离相关,并有利于特征选择。
- 在需要考虑“维度独立贡献”且对欧几里得距离不敏感时,也会选用它。
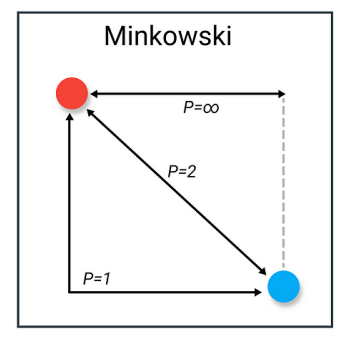
==Minkowski Distance(闵可夫斯基距离)==
是欧几里得距离(p=2)、曼哈顿距离(p=1)等的广义形式,p→∞ 时,就演化为 Chebyshev Distance,公式为:
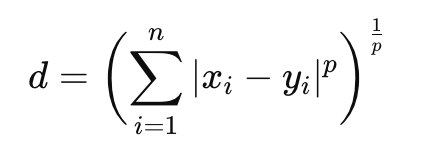
- 提供了一个可调节的尺度,可以根据不同数据分布或需求,选择合适的 p。
- 在实践中常用 p=1(曼哈顿距离)、p=2(欧几里得距离),有时也会用到介于 1 和 2 之间的非整数 p。
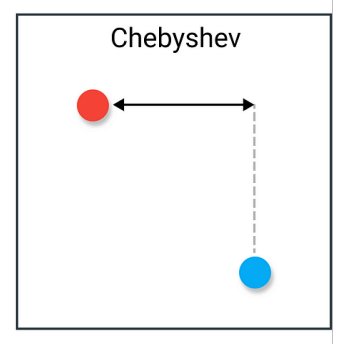
==Chebyshev Distance(切比雪夫距离)(L∞ )==
又称 L∞ 距离,定义为各维度坐标差值绝对值的最大值:
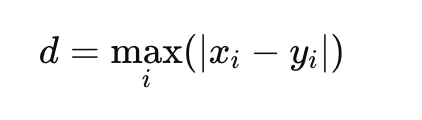
- 适合用在“棋盘距离”概念下:国际象棋中国王走一步最多可以改变行和列各 1,如果两个点在同一个“king move”距离里则 Chebyshev 距离较小。
- 某些最坏情况下的容忍度分析或者要求“任何一维差都不能超过某个限度”的场景,也可以使用 Chebyshev 距离。
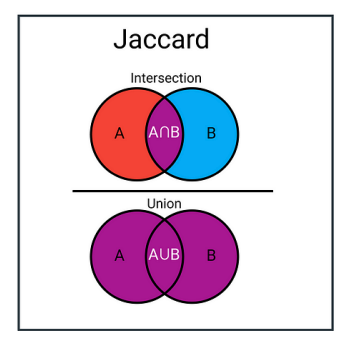
==Jaccard Distance(杰卡德距离)==
Jaccard 相似系数(Jaccard Similarity) 常定义为
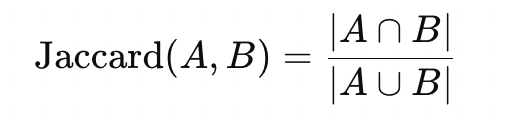
- 专门用来衡量集合之间的相似度或距离,常见于集合、布尔向量或稀疏数据表示场景(例如文档词集合)。
- 在信息检索、推荐系统和社交网络分析(用用户的兴趣标签作为集合)中很常用。
- 当想关注“集合之间真正重叠部分”在整体里的比例时,Jaccard 会更加合适。
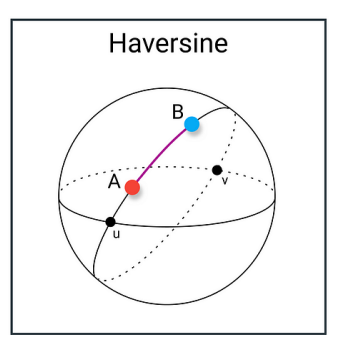
==Haversine Distance(哈夫萨因距离)==
主要用于地球表面上两点之间的球面距离计算。给定两点的经纬度 (lat1,lon1) 和 (lat2,lon2),它基于球面大圆距离公式(Great-circle distance),更加适合实际地理位置的距离估算。
- 适合用在地理坐标(如 GPS 坐标)计算距离的场合,比简单的欧几里得公式更准确地考虑地球的球面特性。
- 地图应用(测算两个地理位置之间的最短飞行距离)、定位服务等都会用到。
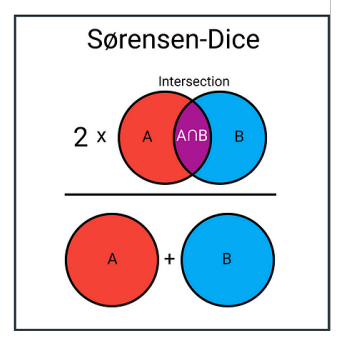
==Sørensen-Dice Coefficient(索伦森-骰子系数)/ Distance==
定义Sørensen-Dice 相似系数通常定义为
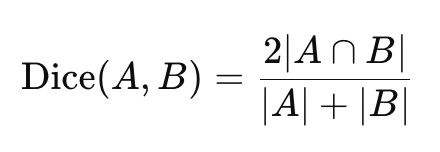
可以引申出相应的距离度量为
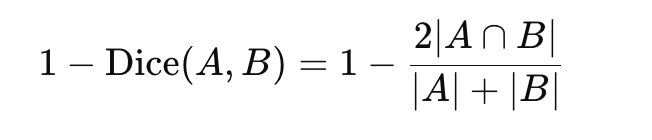
- 与 Jaccard 相似度都属于度量集合或二进制向量相似度的常用指标,但 Dice 会更关注“交集在两个集合规模总和里的占比”。
- 在信息检索、文本挖掘等需要对集合或特征子集比较的场景下常用。
- 对于小规模的集合,Dice 可能更加稳定;而对于大规模稀疏集合,Jaccard 与 Dice 在使用上常可以互换。
2.2.2 向量数据库(以 Milvus 为例)
2.2.2.1 为什么要使用向量数据库?
向量正逐步崭露头角,有望成为AI时代的数据交换标准,而向量数据库,现在有望成为 AI 时代的数据底座
2.2.2.2 Milvus 介绍
整体架构
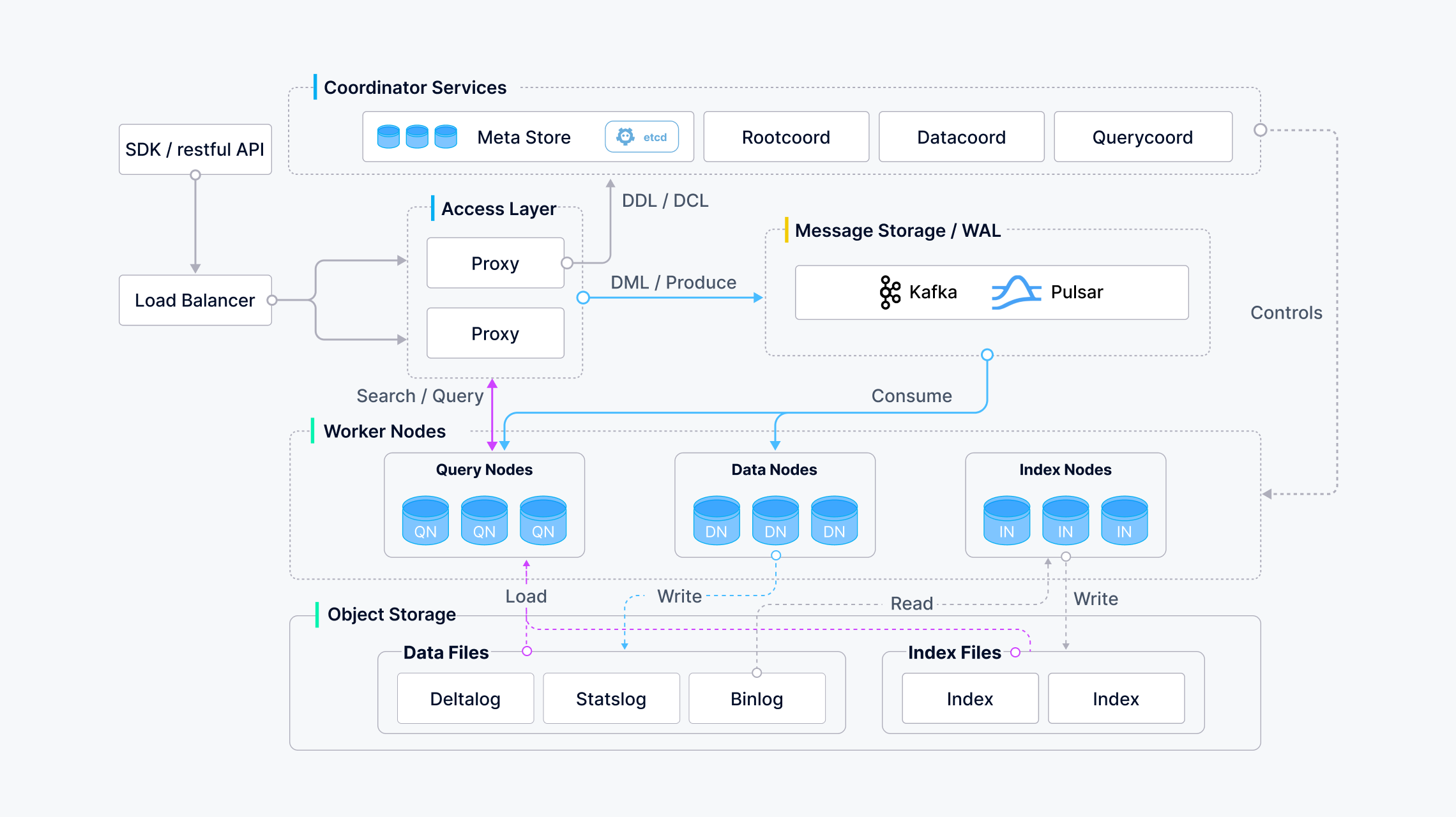
接入层
- LoadBalancer
- 使用 Nginx、Kubernetes Ingress、NodePort 和 LVS 等负载均衡组件提供统一的服务地址
- Proxy
- 代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端
协调服务
- 代理会对中间结果进行聚合和后处理,然后再将最终结果返回给客户端
- Rootcoord
- 根协调器处理数据定义语言(DDL)和数据控制语言(DCL)请求,如创建或删除 Collections、分区或索引,以及管理 TSO(时间戳 Oracle)和时间刻度签发。
- Querycoord
- 数据协调器管理数据节点和索引节点的拓扑结构,维护元数据,并触发刷新、压缩和索引构建以及其他后台数据操作。
- Datacoord
- 数据协调器管理数据节点和索引节点的拓扑结构,维护元数据,并触发刷新、压缩和索引构建以及其他后台数据操作。
工作节点
- QueryNode
- 查询节点通过订阅日志代理检索增量日志数据并将其转化为不断增长的片段,从对象存储中加载历史数据,并在向量和标量数据之间运行混合搜索。
- DataNode
- 数据节点通过订阅日志代理检索增量日志数据,处理突变请求,将日志数据打包成日志快照并存储在对象存储中。
- IndexNode
- 索引节点构建索引。 索引节点不需要常驻内存,可以使用无服务器框架来实现。
存储
-
meta store
- 元存储存储元数据的快照,如 Collections Schema 和消息消耗检查点。元数据的存储要求极高的可用性、强一致性和事务支持,因此 Milvus 选择 etcd 作为元存储。Milvus 还使用 etcd 进行服务注册和健康检查。
-
object storage
- 对象存储用于存储日志快照文件、标量和向量数据的索引文件以及中间查询结果。Milvus 使用 MinIO 作为对象存储。
-
message storage
- 日志代理是一个支持回放的发布子系统。它负责流数据持久化和事件通知。当工作节点从系统故障中恢复时,它还能确保增量数据的完整性。Milvus 集群使用 Pulsar 作为日志代理;Milvus 单机使用 RocksDB 作为日志代理。此外,日志代理可以随时替换为 Kafka 等流式数据存储平台。
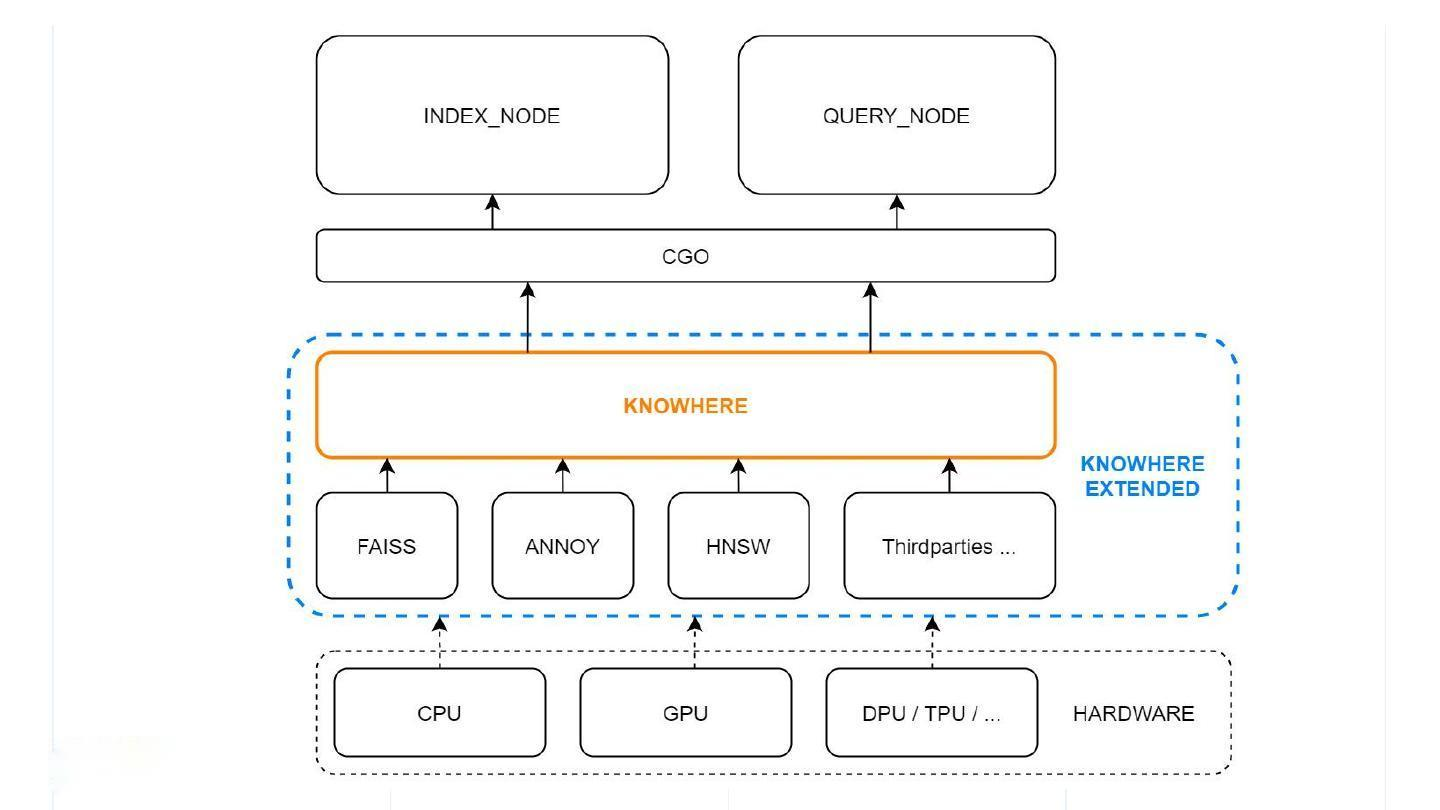
检索引擎 Knowwhere
如果把 Milvus 比喻为一辆跑车,Knowhere 就是这辆跑车的引擎。Knowhere 的定义范畴分为狭义和广义两种。狭义上的 Knowhere 是下层向量查询库(如Faiss、HNSW、Annoy)和上层服务调度之间的操作接口。同时,异构计算也由 Knowhere 这一层来控制,用于管理索引的构建和查询操作在何种硬件上执行, 如 CPU 或 GPU,未来还可以支持 DPU/TPU/……这也是 Knowhere 这一命名的源起 —— know where。广义上的 Knowhere 还包括 Faiss 及其它所有第三方索引库。因此,可以将 Knowhere 理解为 Milvus 的核心运算引擎。
Milvus的数据模型
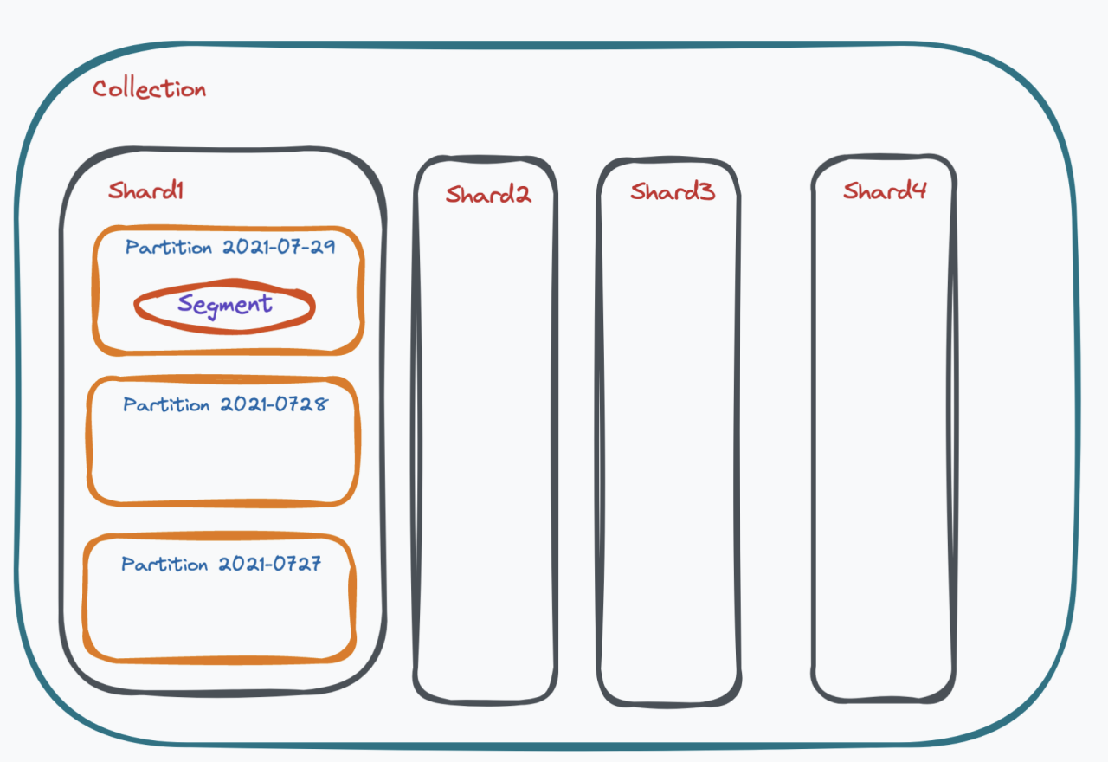
- Database,一个 milvus 集群可以设置多个 database,下属多个 collection
- Collection,因为是分布式系统,所以一个 collection 可以被加载到多个 node 上,每个 node 加载该 collection 的一个分片,每个分片称为 shard
- Partition,数据的逻辑分片,可加速查询
- Segment,是 Partition 中的数据块
在 Milvus 中查询的最小单位是 segment,对 collection 的查询操作最终会被分解为对该 collection 或若干 partition 中所有 segment 的查询。最后,对所有 segment 的查询结果进行归并,并得到最终结果。
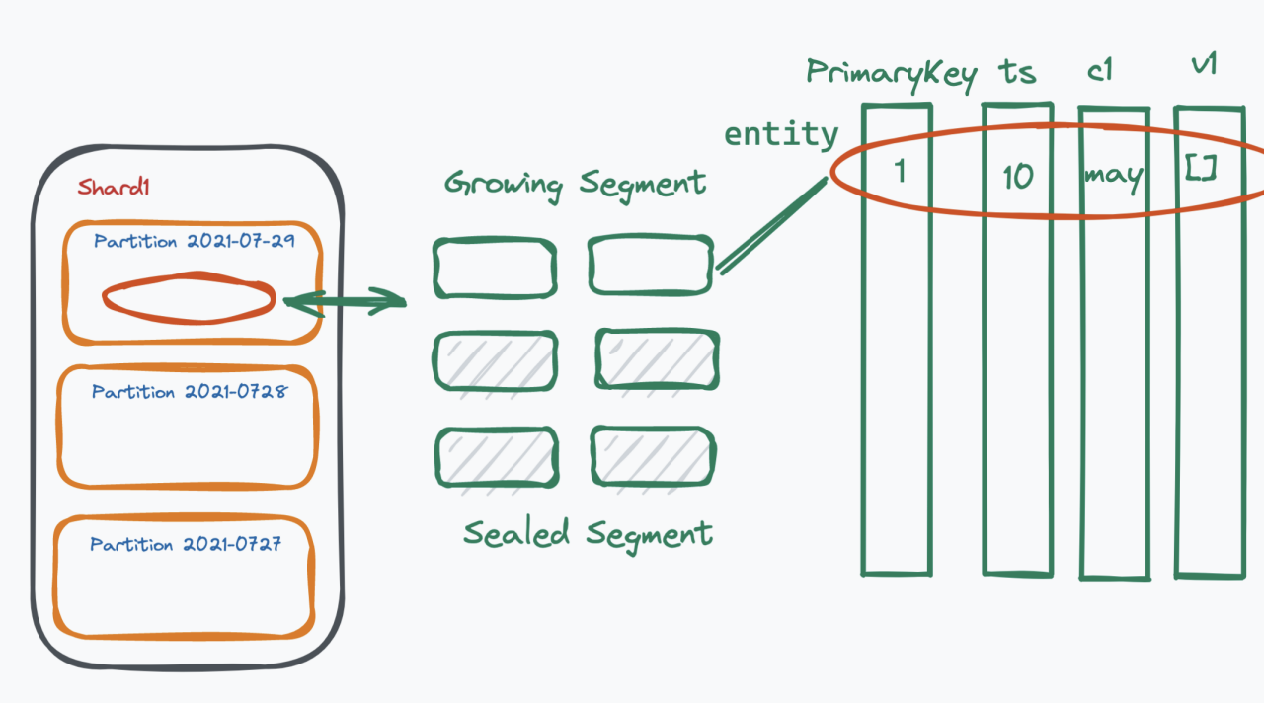
检索引擎的底层执行逻辑
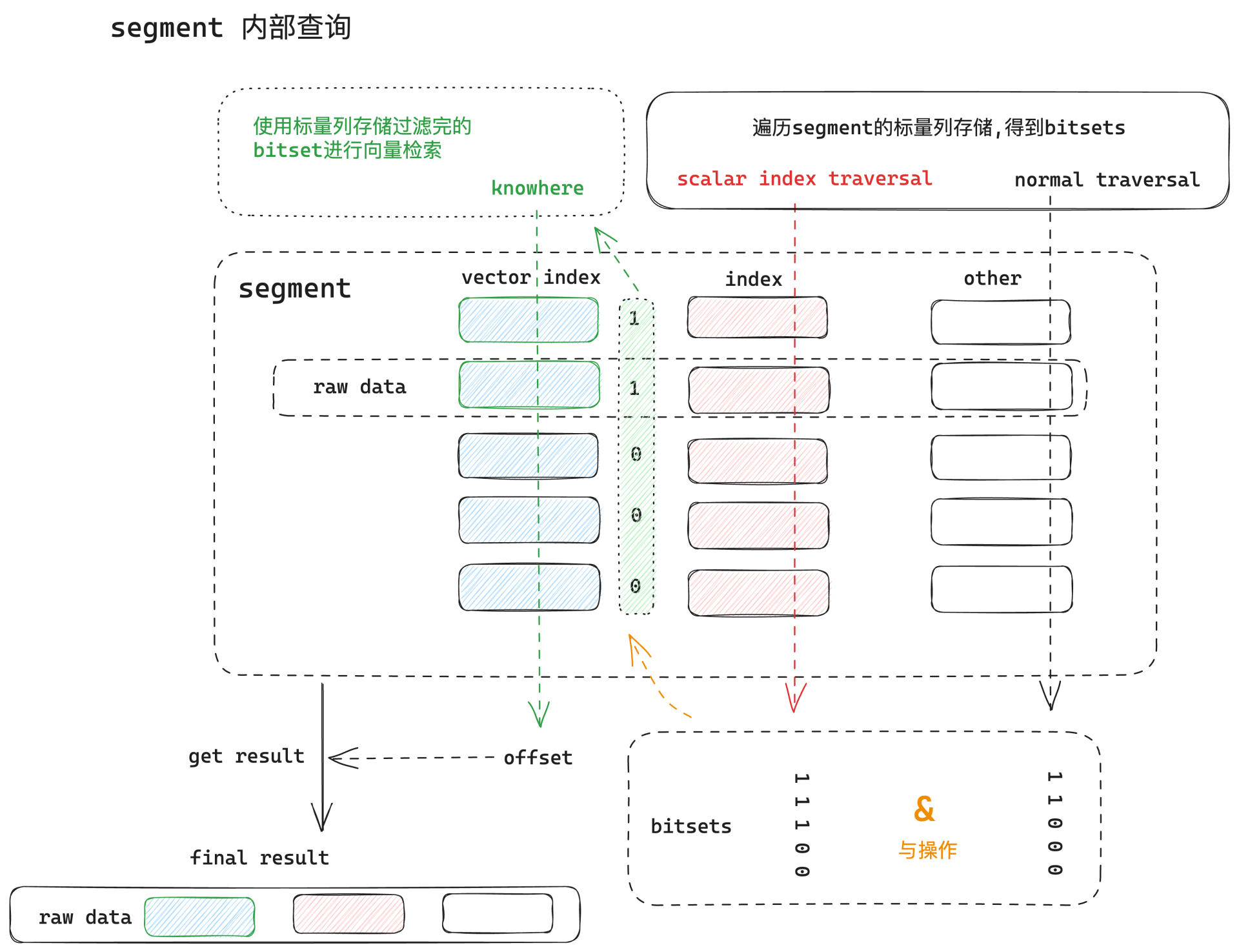
2.2.2.3 向量索引
索引性能benchmark:https://ann-benchmarks.com/index.html
检索方式 KNN VS ANN——检索方式的选择
==KNN (K-Nearest Neighbor)==
在向量检索中表示精确最近邻搜索,目标是找到查询向量在高维空间中真正距离最近的 K 个向量
工作原理
KNN 的核心思想是通过计算查询向量与数据库中每个向量的距离,找到最近的 K 个向量。关键步骤如下:
- 距离度量: 使用欧几里得距离、余弦相似度、内积等度量方式。
- 线性扫描: 遍历所有向量,计算查询点到每个向量的距离,按距离排序,返回前 K 个。
- 数据结构优化:
- KD-Tree: 将数据划分为超平面以加速低维检索。
- Ball Tree: 按距离分割向量点云形成层次结构,适合中低维检索。
优点
- 精确性高: 能保证结果是最精确的 K 个邻居。
- 简单直观: 实现上无需复杂的预处理或索引构建。
缺点
- 计算开销大:
- 如果数据集有 n个向量,每个向量有 d 个维度,则线性扫描需要 O(n×d)的计算。
- 在数据量大或维度高的情况下,性能显著下降(“维度灾难”)。
- 不适合大规模数据: 当数据量或查询次数增加时,响应时间可能过长。
使用场景
- 需要精确结果的应用,如:
- 医疗图像匹配。
- 法律文档检索。
- 高精度推荐系统(小数据集)。
==ANN (Approximate Nearest Neighbor)==
ANN 是一种近似搜索技术,用于快速查找与查询向量相似的邻居,但不保证结果完全精确,允许一定误差。
工作原理
ANN 的核心思想是通过减少计算和搜索范围,以加速检索。关键步骤如下:
- 向量降维:
- 将高维向量映射到低维空间,降低计算复杂度。
- 常见方法:PCA(主成分分析)、随机投影。
- 索引构建:
- 使用特定的数据结构(如哈希表或图)将向量组织成高效的索引。
- 近似查找:
- 使用索引快速缩小检索范围,只计算小部分向量的距离。
常见实现方法
- 基于哈希的技术:LSH (Locality-Sensitive Hashing)
- 核心原理:
- 构建哈希函数组,将相似的向量映射到同一桶中。
- 查询时只需在相关桶中搜索,减少搜索范围。
- 适用场景: 适用于低维数据和欧几里得距离度量。
- 核心原理:
- 基于图的技术:HNSW (Hierarchical Navigable Small World)
- 核心原理:
- 构建分层图,节点表示向量,边表示向量之间的相似性。
- 搜索时从上层开始逐层向下,最终找到近似邻居。
- 优势:
- 高效处理高维数据。
- 在工业界应用广泛(如 Milvus、FAISS)。
- 核心原理:
- 基于量化的技术:PQ (Product Quantization)
- 核心原理:
- 将向量划分为子空间,并为每个子空间创建码本,压缩存储。
- 查询时通过码本进行快速距离计算。
- 优势:
- 存储效率高,适合超大规模数据。
- 核心原理:
- 基于树的技术:Annoy
- 核心原理:
- 构建多个随机分割树,通过投影缩小检索范围。
- 查询时遍历多棵树以找到近似邻居。
- 优势:
- 实现简单,适合分布式场景。
优点
- 实现简单,适合分布式场景。
- 核心原理:
- 速度快: 可显著提升高维和大规模数据的查询速度。
- 扩展性好: 适合处理亿级规模的向量检索。
- 存储优化: 一些方法(如 PQ)还能大幅压缩向量存储。
缺点
- 近似结果: 可能无法找到真正最近的邻居。
- 误差可控性: 需要平衡查询速度与结果精度。
使用场景
- 高速检索需求的应用,如:
- 搜索引擎(Google、Bing)。
- 大规模推荐系统(音乐、视频)。
- 自然语言处理(语义向量检索)。
目前在 AI 领域,主流使用 ANN 索引
量化方式 PQ、SQ——压缩索引大小,降低内存占用
==PQ(Product Quantization)—— 产品量化(乘积量化)==
核心概念
- 产品量化是一种分块量化方法,将高维向量分为多个低维子空间,对每个子空间单独进行量化。
- 核心思想是通过子空间量化实现高效压缩,同时保留全局信息的近似性。
实现步骤
- 向量分块:
- 将高维向量分成 m 个低维子向量。例如,128 维向量可以分为 4 个 32 维子向量。
- 码本训练:
- 对每个子空间单独训练一个码本(通常通过 K-Means 聚类),每个码本中包含 k 个质心(即量化中心点)。
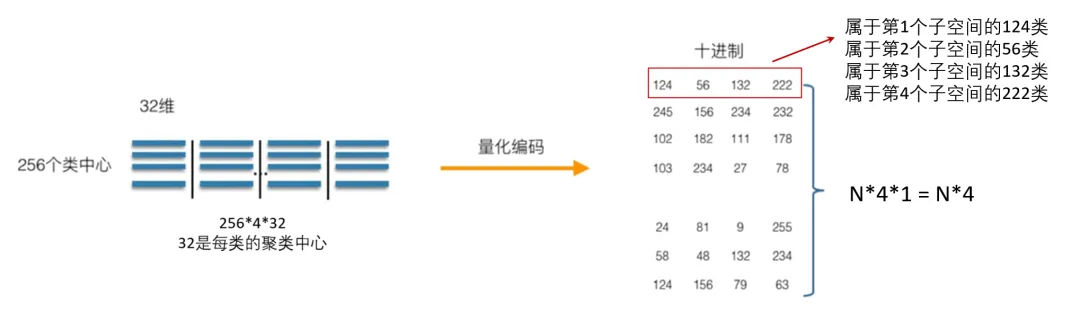
- 量化编码:
- 将每个子向量映射为其所在子空间码本中的最近质心索引。
- 存储的索引比直接存储原始向量占用更少空间。
- 检索时的重构:
- 检索时,将查询向量也分块,依次查询每个子空间的质心,计算近似距离。
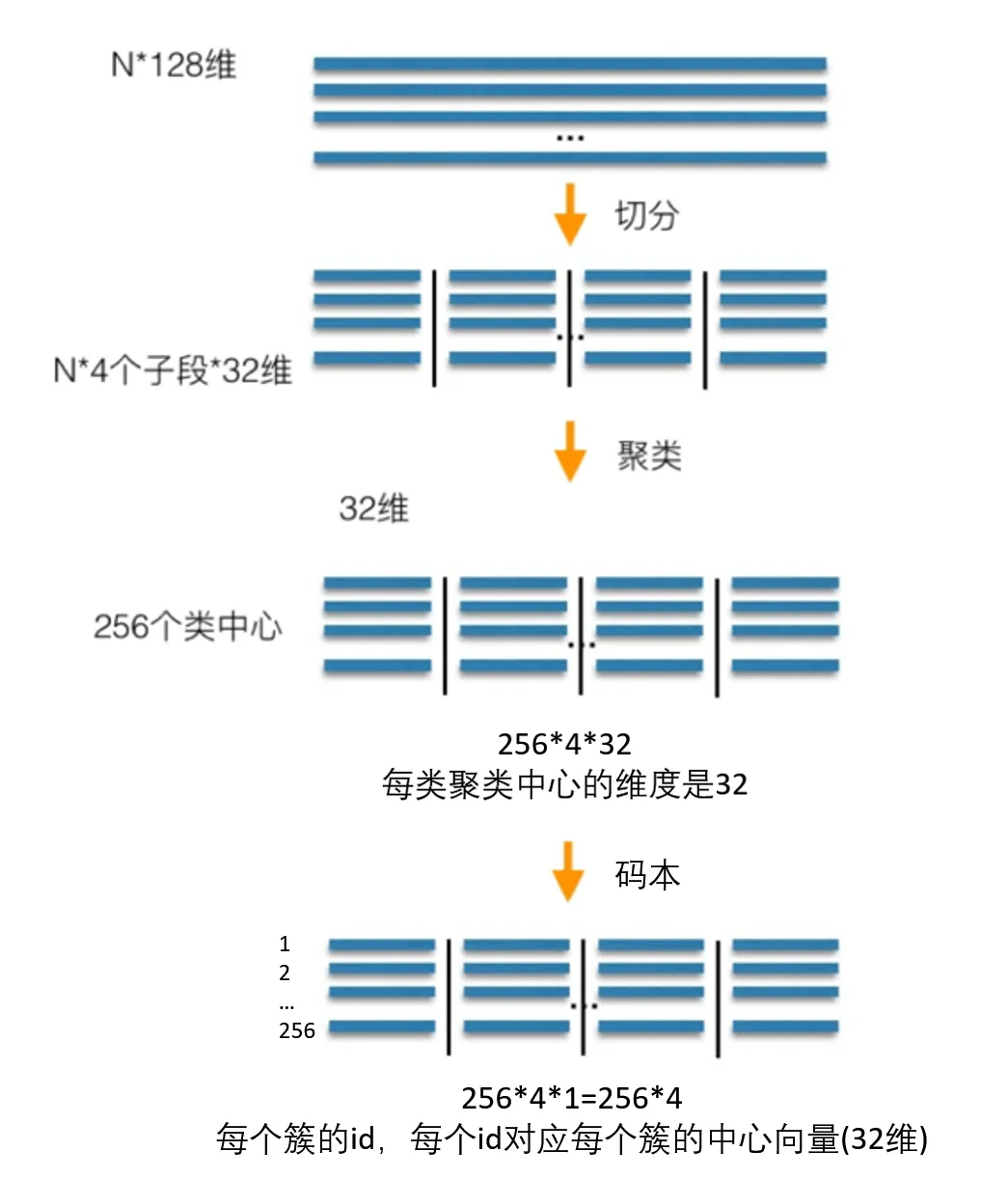
- 检索时,将查询向量也分块,依次查询每个子空间的质心,计算近似距离。
==SQ(Scalar Quantization)—— 标量量化==
核心概念
- 标量量化是对每个向量维度单独进行量化,将其值映射到固定范围内的一组离散值(标量)。
- 核心思想是通过简单的数值离散化压缩向量存储。
实现步骤
- 范围确定:
- 对每个维度的值确定最大值和最小值范围。
- 离散化:
- 将每个维度的值离散到有限数量的标量(如 8 位整数),通常通过线性映射实现:
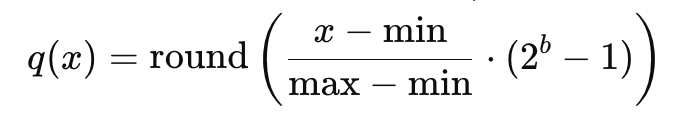
- 将每个维度的值离散到有限数量的标量(如 8 位整数),通常通过线性映射实现:
b 是量化位数。
- 存储:
- 存储离散值的索引代替原始值。
聚类算法——K-Means
聚类(Clustering) 简而言之,就是使用某种静态分类方法将一组数据自动地分成多个子集。由于研究对象和使用场景不同,聚类算法的种类也十分多样。常见的模型包括 Connectivity 和 Centroid 等,而 K-Means 则是 Centroid 模型的典型代表之一。
以下是 K-Means 聚类的流程:
- **随机选定重心(Centroid):**在数据集中随机选取 k 个点,并将它们视为初始的重心。
- **划分子集:**根据这 k 个重心把数据分成 k 个子集,每个子集都对应一个重心。
- **分配数据点:**对数据集中的每个向量与各重心进行距离计算,并将其分配给距离最近的重心所对应的子集。
- **更新重心并迭代:**重新计算各子集的重心,使其在该子集内更加均匀。随后重复步骤 2 和 3,通常进行多次迭代(i 次)直到收敛或达到预定的迭代次数。
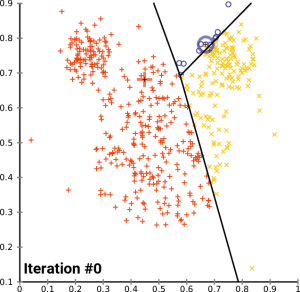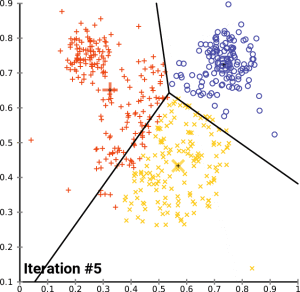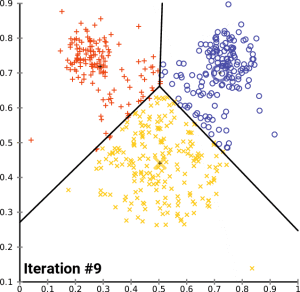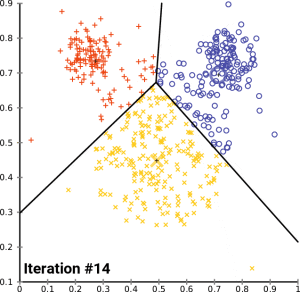
倒排文件索引 IVF
概念:
- 将高维向量数据划分为多个组(或称“桶”)。
- 每个组对应一个“倒排表”(Inverted List),存储属于该组的向量。
- 查询时,首先确定查询向量属于哪个组,只在该组的倒排表中进行进一步搜索,从而减少计算量
实现步骤
- 聚类分桶:
- 通过聚类算法(如 K-Means)将数据库向量分成 K 个簇。
- 每个簇的中心点称为簇心或质心,所有簇心组成一个“簇心集合”。
- 每个簇对应一个倒排表,存储落在该簇中的所有向量的索引。
- 构建倒排文件:
- 数据库中的每个向量都根据与簇心的距离,分配到最近的簇。
- 簇内的向量索引存储在对应的倒排表中。
- 查询阶段:
- 对查询向量进行近似检索:
- 首先计算查询向量到所有簇心的距离,找到最近的 n 个簇(称为“候选簇”)。
- 在这些候选簇的倒排表中,进行精确或近似的最近邻搜索。
- 对查询向量进行近似检索:
索引枚举
==FLAT——暴力检索的实现==
FLAT 的精确度很高,因为它采用的是穷举搜索方法,这意味着每次查询都要将目标输入与数据集中的每一组向量进行比较。这使得 FLAT 成为我们列表中速度最慢的索引,而且不适合查询海量向量数据。在 Milvus 中,FLAT 索引不需要任何参数,使用它也不需要数据训练。
==IVF_FLAT——倒排暴力检索==
IVF_FLAT 将向量数据划分为nlist 个聚类单元,然后比较目标输入向量与每个聚类中心之间的距离。根据系统设置查询的簇数 (nprobe),相似性搜索结果将仅根据目标输入与最相似簇中向量的比较结果返回--大大缩短了查询时间。
通过调整nprobe ,可以在特定情况下找到准确性和速度之间的理想平衡。IVF_FLAT 性能测试结果表明,随着目标输入向量数 (nq) 和要搜索的簇数 (nprobe) 的增加,查询时间也会急剧增加。
IVF_FLAT 是最基本的 IVF 索引,每个单元中存储的编码数据与原始数据一致。
==IVF_SQ8——倒排 SQ 量化索引,减少 70-75% 的磁盘、CPU 和 GPU 内存消耗==
IVF_FLAT 不进行任何压缩,因此它生成的索引文件大小与原始的非索引向量数据大致相同。例如,如果原始的 1B SIFT 数据集为 476 GB,那么其 IVF_FLAT 索引文件就会稍小一些(~470 GB)。将所有索引文件加载到内存中将消耗 470 GB 的存储空间。
当磁盘、CPU 或 GPU 内存资源有限时,IVF_SQ8 是比 IVF_FLAT 更好的选择。这种索引类型可以通过执行标量量化(SQ)将每个 FLOAT(4 字节)转换为 UINT8(1 字节)。这样可以减少 70-75% 的磁盘、CPU 和 GPU 内存消耗。对于 1B SIFT 数据集,IVF_SQ8 索引文件仅需 140 GB 的存储空间。
==IVF_PQ——倒排 PQ 量化,索引文件比 IVF_SQ8 更小==
PQ (乘积量化)将原始高维向量空间均匀分解为 低维向量空间的笛卡尔乘积,然后对分解后的低维向量空间进行量化。乘积量化不需要计算目标向量与所有单元中心的距离,而是能够计算目标向量与每个低维空间聚类中心的距离,大大降低了算法的时间复杂度和空间复杂度。
IVF_PQ 先进行 IVF 索引聚类,然后再对向量的乘积进行量化。其索引文件比 IVF_SQ8 更小,但在搜索向量时也会造成精度损失。
| 参数 | 说明 |
|---|---|
nlist | 集群单位数 |
m | 乘积量化因子数 |
nbits | [可选项] 每个低维向量的存储位数。 |
nprobe | 要查询的单位数 |
==SCANN —— Google 推出的非常先进的索引==
https://github.com/google-research/google-research/tree/master/scann
ScaNN(可扩展近邻)在向量聚类和乘积量化方面与 IVF_PQ 相似。它们的不同之处在于乘积量化的实现细节和使用 SIMD(单指令/多数据)进行高效计算。
==HNSW——主流的图索引==
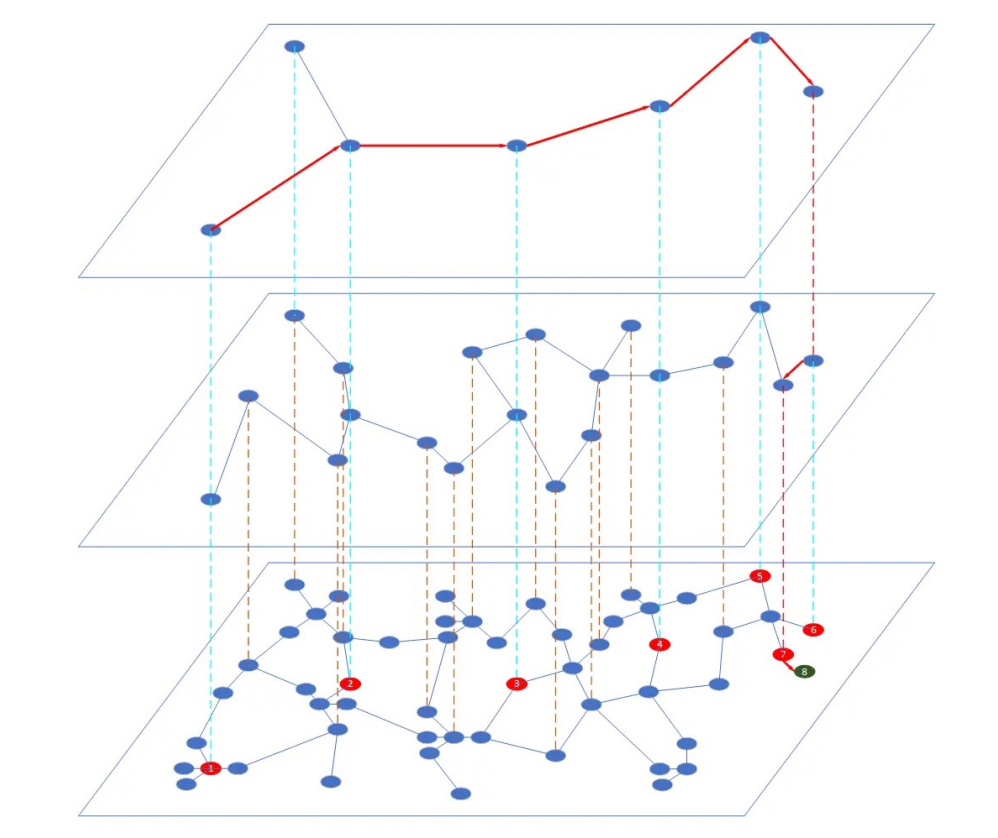
HNSW(分层导航小世界图)是一种基于图的索引算法。它根据一定的规则为图像建立多层导航结构。在这个结构中,上层较为稀疏,节点之间的距离较远;下层较为密集,节点之间的距离较近。搜索从最上层开始,在这一层找到离目标最近的节点,然后进入下一层开始新的搜索。经过多次迭代后,就能快速接近目标位置。
HNSW索引在构建过程中,必须由⽤户指定的建索引参数,除了距离算法之外,只有2个参数:
- M:给每个新插⼊的点建议的边的数量,M的合理值在2和200之间,⼀般来说,M越⼤,检索的召回率也会更好,但是图结构占⽤的额外索引空间也会越⼤,M=16或32都是⽐较常⻅的选择
- efConstruction:建索引过程中,每个点的候选最近邻数量,该参数越⼤,索引的质量越好,建索引的计算量也越⼤,该参数对建索引的耗时有⾮常⼤的影响,取值⼀般为M的数倍⾄⼀个数量级,100或200都是常⻅的取值选择
HNSW索引性能退化
在带过滤的检索场景中,如果被过滤掉的数据⽐例超过⼀定的阈值之后,HNSW索引的召回率会急剧下降,甚⾄是检
索延迟的急剧上升,使得算法失效。此问题在算法层⾯⾄今尚未得到很好的解决,已有的解决⽅法包括:
- 设定更⼤的M值,从图可以看出,M越⼤,退化点越靠右,但更⼤的M也会带来更⼤的内存开销
- 设定过滤⽐例阈值底线,⽐如5%、7%等,当满⾜过滤条件的数据不⾜这个⽐例时,直接退化为KNN检索

==HNSW_PQ——HNSW PQ 量化索引==
HNSW PQ 量化索引,详情参考HNSW
==HNSW_SQ——HNSW SQ 量化索引==
HNSW SQ 量化索引,详情参考HNSW
索引使用场景比较
| 索引 | 场景 |
|---|---|
| FLAT | - 数据集相对较小 - 需要 100% 的召回率 |
| IVF_FLAT | - 高速查询 - 要求尽可能高的召回率 |
| IVF_SQ8 | - 极高速查询 - 内存资源有限 - 可接受召回率略有下降 |
| IVF_PQ | - 高速查询 - 内存资源有限 - 可略微降低召回率 |
| HNSW | - 极高速查询 - 要求尽可能高的召回率 - 内存资源大 |
| HNSW_SQ | - 非常高速的查询 - 内存资源有限 - 可略微降低召回率 |
| HNSW_PQ | - 中速查询 - 内存资源非常有限 - 在召回率方面略有妥协 |
| SCANN | - 极高速查询 - 要求尽可能高的召回率 - 内存资源大 |
2.2.2.4 向量数据库的使用优化
成本优化
在向量数据库实际使用过程中,主要的成本在于 内存、CPU、磁盘,从占比上来说,内存成本远远高于 CPU 和磁盘,所以,一般我们通过优化内存占用,来进行成本优化,一般通过调优索引来实现
稳定性优化
Milvus 大部分节点是无状态服务,有状态服务需要进行稳定性优化的,一般是 ETCD、MinIO,关于 ETCD 和 MinIO 优化不展开
2.2.3 什么是 RAG
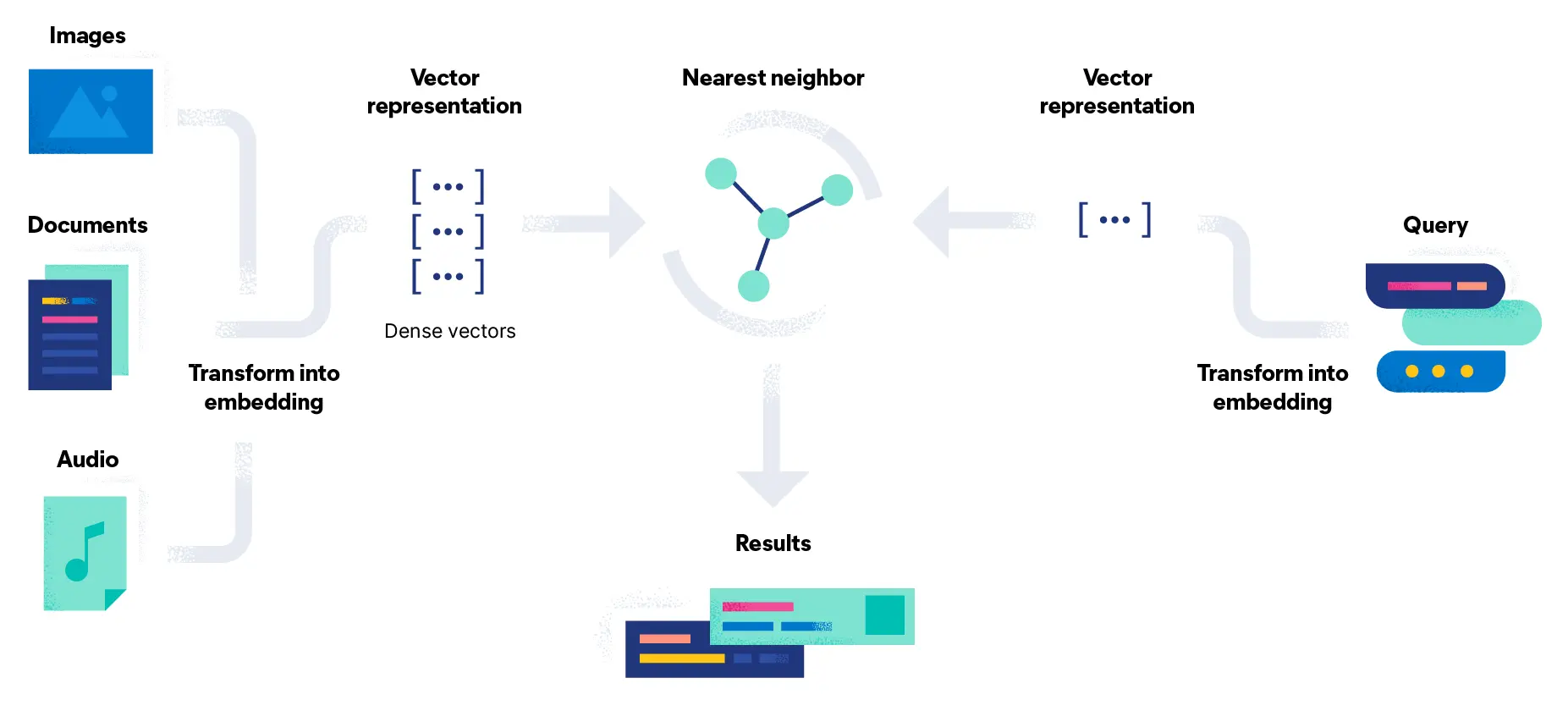
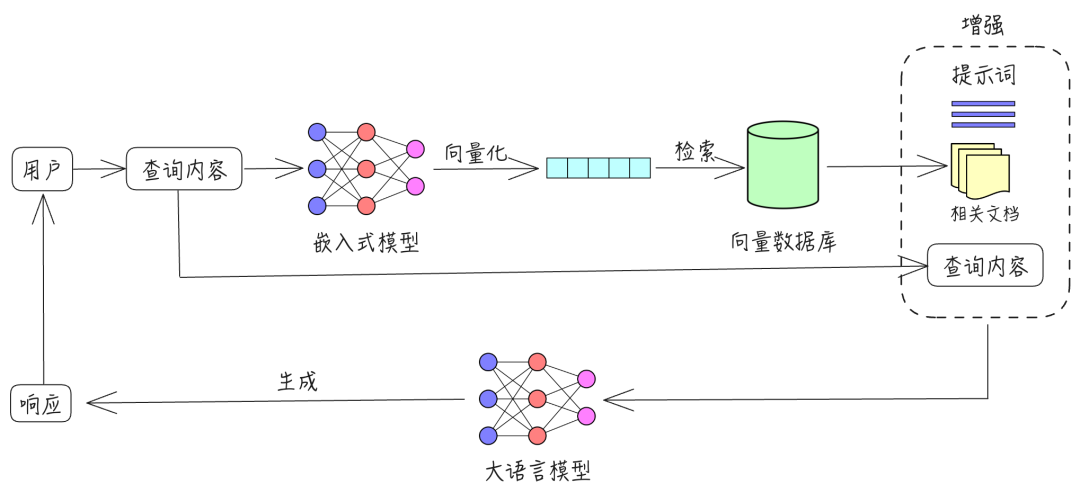
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索和文本生成的大模型架构,用于在生成过程中动态检索外部知识库中的相关信息,以提高生成内容的准确性和时效性。RAG 通过检索机制引入实时的信息,使得模型在回答问题时可以更具针对性地使用最新、最相关的知识。
RAG 包含三个主要过程:检索、增强和生成。
- 检索:根据用户的查询内容,从外部知识库获取相关信息。具体而言,将用户的查询通过嵌入模型转换为向量,以便与向量数据库中存储的相关知识进行比对。通过相似性搜索,找出与查询最匹配的前 K 个数据。
- 增强:将用户的查询内容和检索到的相关知识一起嵌入到一个预设的提示词模板中。
- 生成:将经过检索增强的提示词内容输入到大型语言模型中,以生成所需的输出。
如图所示为一个最原始的RAG的查询流程
2.2.4 RAG 的技术架构
RAG技术架构主要由两个核心模块组成,检索模块(Retriever)和生成模块(Generator)。
- 检索模块(Retriever):
- 文本嵌入:使用预训练的 Embedding 模型将查询和文档转换成向量表示,以便在向量空间中进行相似度计算。
- 向量搜索:利用高效的向量搜索技术(如FAISS、Milvus等向量数据库)在向量空间中检索与查询向量最相似的文档或段落。
- 双塔模型:检索模块常采用双塔模型(Dual-Encoder)进行高效的向量化检索。双塔模型由两个独立的编码器组成,一个用于编码查询,另一个用于编码文档。这两个编码器将查询和文档映射到相同的向量空间中,以便进行相似度计算。
- 生成模块(Generator):
- 强大的生成模型:生成模块通常使用在大模型,这些模型在生成自然语言文本方面表现出色。
- 上下文融合:生成模块将检索到的相关文档与原始查询合并,形成更丰富的上下文信息,作为生成模型的输入。
- 生成过程:生成模型根据输入的上下文信息,生成连贯、准确且信息丰富的回答或文本。
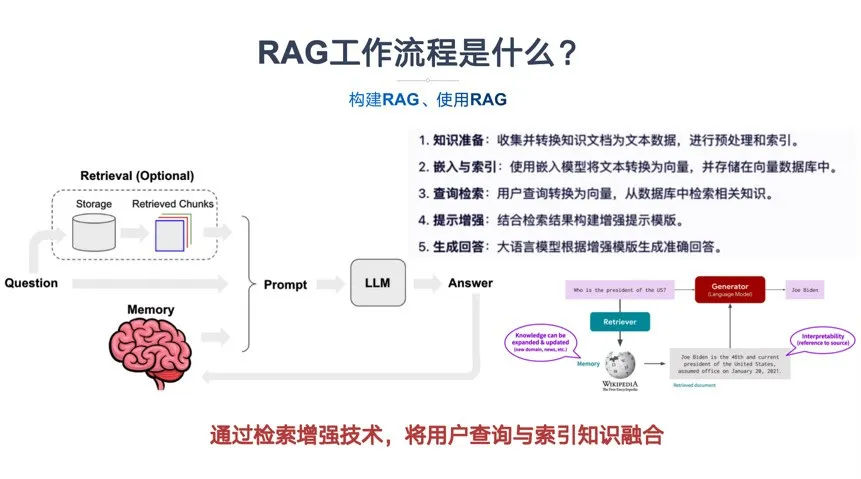
2.2.5 RAG的工作流程
通过检索增强技术,将用户查询与索引知识融合,利用大语言模型生成准确回答。
- 知识准备:收集并转换知识文档为文本数据,进行预处理和索引。
- 嵌入与索引:使用嵌入模型将文本转换为向量,并存储在向量数据库中。
- 查询检索:用户查询转换为向量,从数据库中检索相关知识。
- 提示增强:结合检索结果构建增强提示模版。
- 生成回答:大语言模型根据增强模版生成准确回答。
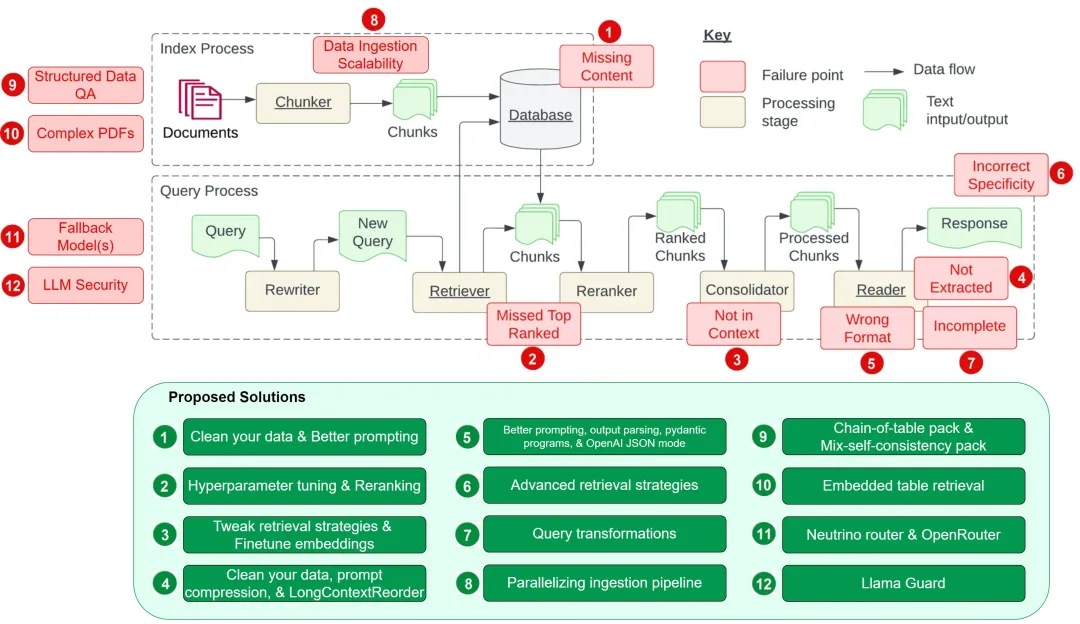
2.2.6 RAG 遇到的挑战及解决方案
挑战的归纳来源于:https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c
缺失内容
当 RAG 系统无法在知识库中找到所需信息时,往往会给出一个看似合理却实际错误的答案,而不是直接说明自己无法回答。这样一来,用户不仅得不到正确信息,还可能被误导,进而产生困惑和挫败感。
数据清洗
如果原始数据充满错误或相互矛盾,无论如何搭建 RAG 处理流程,都无法将混乱的输入转换为有价值的输出。因此,高质量的数据是构建任何有效的 RAG 流程的前提条件。
- 如果在知识库中存在大量不一致或过时的信息,模型就很难给出准确答案。
- 定期对数据进行清理、更新和维护,能显著提高系统的可靠性与准确度。
提示词工程
当知识库中缺少必要信息时,系统可能编造出貌似合理但实际错误的回答。这时,一个设计良好的 Prompt 可以大大减少误导性信息的产生:
-
示例提示:
“如果你对答案不确定,就告诉我你不知道。” -
作用:
-
-
鼓励模型在缺少可靠信息时承认自己的局限性,明确表示不确定或无法回答。
-
提高回答透明度,让用户了解模型可能存在的信息盲区。
-
- 效果:
虽然不能百分百避免错误,但在做好数据清洗的基础上,恰当的提示词设计是提高回答质量的重要手段之一。
关键文档被遗漏
有时候,重要的文档可能不会出现在系统返回的最顶端结果中,导致正确的答案被忽略,系统未能提供准确的反馈。正如一篇研究所暗示的那样:“答案虽然在文档中,但因为排名不够高而未能展现给用户”。
调整分块策略(chunking)
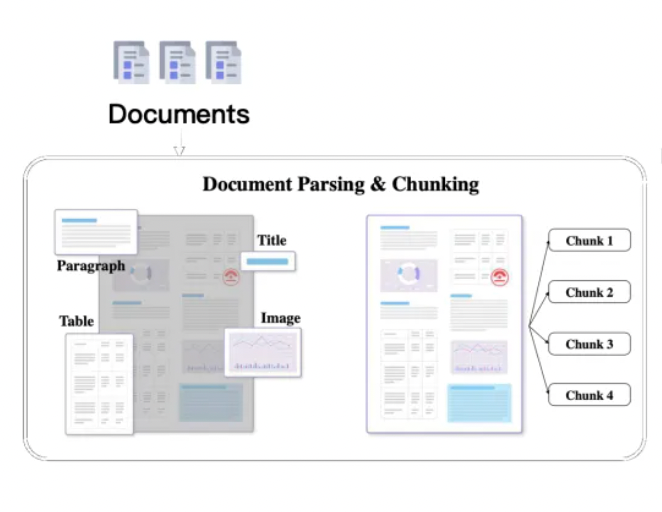
- 文本分块策略对大模型输出的影响
- 文本分块过长的影响
- 语义模糊:当文本块过长时,在向量化的过程中,大量词汇信息需要被压缩到一个固定长度的向量表示中,细节语义往往被平均化或淡化。换言之,模型难以精准捕捉文本的核心主题与关键细节,因而生成的向量无法全面反映文本的重要内容,降低了对文本理解的准确度。
- 降低召回精度:在检索阶段,系统会根据用户的查询从向量数据库中搜索相关文本。然而,如果文本块过长,往往涉及多个主题或观点,语义信息变得更加复杂。检索模型难以准确匹配用户的查询意图,导致召回的文本相关性下降,进而影响大模型生成答案的质量
- 输入受限:当前大语言模型对输入长度有严格限制。过长的文本块会占据更多的输入空间,使可输入到模型的其他文本块数量变少。这样一来,模型能够访问的信息广度受到限制,可能错失重要的上下文或相关信息,最终影响模型的回答效果。
- 文本分块过短的影响
-
上下文缺失:当文本块过短时,往往缺乏足够的上下文信息。由于上下文对于理解语言意义至关重要,信息过于分散会导致模型难以准确把握文本含义,生成的回答可能因此不完整或偏离主题
-
主题信息丢失:某些段落或章节需要足够的文本长度来表达整体主题或核心概念。过短的文本块只包含片段信息,难以呈现完整的观点脉络,影响模型对整体内容的把握与理解。
-
碎片化问题:过多的短文本块会造成信息过度碎片化,增加检索和处理的复杂度。系统必须处理更多的文本块,会带来额外的计算与存储开销。同时,大量碎片化的信息可能扰乱模型的判断逻辑,进而降低系统的整体性能和回答质量。
-
- 文本分块过长的影响
==常见的文本分块策略==
- 固定大小分块:简单直观的文本分块方式
固定大小文本切块是一种最简单、最直接的文本分块方法。它按照预先设定的固定长度,将文本硬性地划分为若干块。这种方法实现成本低且快速,但在实际应用中也会面临一些问题,需要相应的改进措施。
- 问题与挑战
- 上下文割裂:若仅依据固定字符数进行截断,可能会打断句子或段落,导致上下文信息丢失。这样不仅会影响后续的文本向量化效果,还会削弱整体的语义理解。
- 语义完整性受损:文本块中若包含不完整的句子或意思,会影响检索阶段对信息的准确匹配,也会降低大模型在回答时的质量。
- 改进方法
- 引入重叠:在相邻文本块之间设定一定的重叠部分,例如令相邻块在切分边界处有 50 个字符的重叠。这样可以在一定程度上保留句子的完整性与段落的连贯性,减少因硬性切分造成的语义割裂。
- 智能截断:尽量在标点符号、段落结束处等自然边界进行切分,而不是严格依赖字符数或固定长度。此举能有效避免打断句子,使得文本块在语义上更加完整。
- 基于 NTLK 分块
NLTK(Natural Language Toolkit) 是广泛使用的 Python 自然语言处理库,提供了丰富的文本处理功能。其中,sent_tokenize 方法可用于自动将文本切分为句子。
原理:sent_tokenize 基于论文《Unsupervised Multilingual Sentence Boundary Detection》的方法,使用无监督算法为缩写词、搭配词和句子开头的词建立模型,然后利用这些模型识别句子边界。这种方法在多种语言(主要是欧洲语言)上都取得了良好效果。
预训练模型缺失:NLTK 官方并未提供中文分句模型的预训练权重,需要用户自行训练。
训练接口可用:NLTK 提供了训练接口,用户可以基于自己的中文语料库训练分句模型。
from langchain.text_splitter import NLTKTextSplitter
text_splitter = NLTKTextSplitter()
text = "..."# 待处理的文本
texts = text_splitter.split_text(text)
for doc in texts:
print(doc)
- 特殊格式分块 (HTML、Markdown)
在实际应用中,常常需要处理具有特殊内在结构的文本,如 HTML、Markdown、LaTeX、代码文件 等。这些文本的结构信息对于理解其内容至关重要,简单的文本切分方法可能会破坏其原有结构,导致上下文信息丢失。
- 保留结构信息:在切分文本时,应尽量保留其内在的结构,如标签、标题、代码块等。
- 减少上下文损失:避免在关键位置切分文本,以免丢失重要的上下文信息。
- 基于语义文本切块
- Embedding-based 方法
- LlamaIndex和 Langchain都提供了基于嵌入(embedding)的 semantic chunker(能够将文本或数据按照语义信息进行分块的工具或算法。)
- 核心思路:利用嵌入(embedding)向量衡量文本片段间的相似度,实现按语义信息进行切分。
- 原理概述:通过滑动窗口(combined_sentence)计算相邻句子的文本相似度。若相似度高于预定阈值,这些句子将被归为同一个语义块;若低于阈值,则视为新的片段起点。
- 优势:
- 实现相对简单,依赖已训练好的 embedding 模型即可完成初步的语义聚合。
- 与 LlamaIndex、Langchain 等框架结合时,易于与向量数据库搭配使用,便于后续检索和问答流程。
- 局限性:
- 对于复杂的上下文依赖或长距离语义信息,单纯的邻近相似度可能不足以准确区分是否应切分。
- 分块结果依赖于阈值设置,对不同文本类型与场景需多次实验调参。
- LlamaIndex和 Langchain都提供了基于嵌入(embedding)的 semantic chunker(能够将文本或数据按照语义信息进行分块的工具或算法。)
- Model-based 方法
- **基于 BERT 的文本切分方法:**在文本上采用滑动窗口,将相邻两个句子分别输入 BERT 模型进行二分类预测;若预测得分较低,即判定这两个句子语义关联度弱,可视为切分点。然而,这种方法存在一定的局限性:
- 上下文信息有限:仅考虑前后两个句子的关系,缺乏更长距离的上下文信息,可能导致切分不准确。
- 计算效率低:需对文本中每对相邻句子进行预测,当文本规模较大时,计算成本较高。
- Cross-Segment 模型
- 引入更长的上下文依赖,一次性考虑多个连续句子,以弥补上一方法的不足。
- 句子向量化:利用 BERT 为每个句子单独提取向量表示,保留基本语义信息。
- 跨段落预测:将多个连续句子的向量共同输入到另一模型(如 BERT 或 LSTM)中,一次预测哪些句子是切分边界。
- 句子向量化部分仍是独立进行,未完全建模句子间的复杂依赖;且需要额外的模型来做跨段预测。
- 引入更长的上下文依赖,一次性考虑多个连续句子,以弥补上一方法的不足。
- SeqModel 模型:自适应滑动窗口与上下文建模
- 同时编码多个句子:直接利用 BERT 对连续的多个句子进行联合编码,在同一次前向传播中捕捉句子间的依赖关系。
- 预测切分边界:在获取上下文增强后的句子表示后,模型判定是否需要在某个句子后进行文本切分。
- 自适应滑动窗口:根据文本内容动态调整窗口大小,不仅提升准确性,也兼顾推理效率。
- **基于 BERT 的文本切分方法:**在文本上采用滑动窗口,将相邻两个句子分别输入 BERT 模型进行二分类预测;若预测得分较低,即判定这两个句子语义关联度弱,可视为切分点。然而,这种方法存在一定的局限性:
- LLM-based 方法
- 题为《 Dense X Retrieval: What Retrieval Granularity Should We Use? 》的论文介绍了一种新的检索单位,称为 proposition 。proposition 被定义为文本中的 atomic expressions(不能进一步分解的单个语义元素,可用于构成更大的语义单位) ,用于检索和表达文本中的独特事实或特定概念,能够以简明扼要的方式表达,使用自然语言完整地呈现一个独立的概念或事实,不需要额外的信息来解释。
- LLamaindex 实现:
PROPOSITIONS_PROMPT = PromptTemplate(
"""Decompose the "Content" into clear and simple propositions, ensuring they are interpretable out of
context.
1. Split compound sentence into simple sentences. Maintain the original phrasing from the input
whenever possible.
2. For any named entity that is accompanied by additional descriptive information, separate this
information into its own distinct proposition.
3. Decontextualize the proposition by adding necessary modifier to nouns or entire sentences
and replacing pronouns (e.g., "it", "he", "she", "they", "this", "that") with the full name of the
entities they refer to.
4. Present the results as a list of strings, formatted in JSON.
Input: Title: ¯Eostre. Section: Theories and interpretations, Connection to Easter Hares. Content:
The earliest evidence for the Easter Hare (Osterhase) was recorded in south-west Germany in
1678 by the professor of medicine Georg Franck von Franckenau, but it remained unknown in
other parts of Germany until the 18th century. Scholar Richard Sermon writes that "hares were
frequently seen in gardens in spring, and thus may have served as a convenient explanation for the
origin of the colored eggs hidden there for children. Alternatively, there is a European tradition
that hares laid eggs, since a hare’s scratch or form and a lapwing’s nest look very similar, and
both occur on grassland and are first seen in the spring. In the nineteenth century the influence
of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular throughout Europe.
German immigrants then exported the custom to Britain and America where it evolved into the
Easter Bunny."
Output: [ "The earliest evidence for the Easter Hare was recorded in south-west Germany in
1678 by Georg Franck von Franckenau.", "Georg Franck von Franckenau was a professor of
medicine.", "The evidence for the Easter Hare remained unknown in other parts of Germany until
the 18th century.", "Richard Sermon was a scholar.", "Richard Sermon writes a hypothesis about
the possible explanation for the connection between hares and the tradition during Easter", "Hares
were frequently seen in gardens in spring.", "Hares may have served as a convenient explanation
for the origin of the colored eggs hidden in gardens for children.", "There is a European tradition
that hares laid eggs.", "A hare’s scratch or form and a lapwing’s nest look very similar.", "Both
hares and lapwing’s nests occur on grassland and are first seen in the spring.", "In the nineteenth
century the influence of Easter cards, toys, and books was to make the Easter Hare/Rabbit popular
throughout Europe.", "German immigrants exported the custom of the Easter Hare/Rabbit to
Britain and America.", "The custom of the Easter Hare/Rabbit evolved into the Easter Bunny in
Britain and America." ]
Input: {node_text}
Output:"""
)
- 前沿分块方法探索
Meta-Chunking (2024.8.16)
标题:Meta-Chunking: Learning Efficient Text Segmentation via Logical Perception,
github:https://github.com/IAAR-Shanghai/Meta-Chunking/tree/386dc29b9cfe87da691fd4b0bd4ba7c352f8e4ed
Meta-Chunking旨在通过对文本进行更灵活的分块来优化 RAG(Retrieval-Augmented Generation)的效果,特别适用于知识密集型任务。它在句子和段落之间引入了一个新的粒度(Meta-Chunk),让一段文本内具有深层语言逻辑联系的多个句子保留逻辑完整性,避免在分段时打断核心语义链。核心原则是允许块大小动态变化,以捕捉并维护内容的逻辑连贯,从而减少检索的噪音并提高内容清晰度。实验表明,这种方法能在 11 个数据集上显著提升单跳和多跳问答的性能。
基于一个核心原则:允许块大小变化,以更有效地捕获和维护内容的逻辑完整性。这种动态的粒度调整可确保每个分段块都包含完整且独立的思想表达,从而避免在分段过程中逻辑链中断。这不仅增强了文档检索的相关性,还提高了内容清晰度。
两种分块策略:
-
Margin Sampling Chunking,将文本切分为句子,再利用 LLM(Large Language Model)对相邻句子做“是否应在此处切分”的二分类预测,如果对“是”与“否”的概率差(Margin)大于某个阈值,就在这两句之间分段;否则视为同一块。
-
Perplexity Chunking,先把文本拆分成句子,并计算每个句子的 PPL(Perplexity),若某个句子在上下文中的 PPL 值偏高,说明它与前后句的衔接较弱,可将此处设为切分点,若块过于零散,则通过动态合并策略来保障分块的合理性。相比传统的固定长度切分或简单的句子/段落级切分,Meta-Chunking 通过更灵活的粒度控制与逻辑感知,可在保证计算效率的同时,更好地维护文本的整体语义与思路衔接,为 RAG 场景中的检索与生成提供更高质量的支持。
检索重排序(reranker)
在检索过程中,前 K 个结果虽然都具有相关性,但最相关的信息可能不在排名靠前的位置。检索重排序(reranker)的主要目标是进一步提升检索结果与用户查询的匹配度,即便前 K 个检索结果本身都与查询相关,也可能存在真正最相关的文档并未排在前几位。通过对这些结果进行重新排序,可以让最有价值或最契合用户需求的信息排在更显眼的位置,从而提高整体检索与后续处理的准确性和效率。
具体 rerank 思路与方法
- Diversity Ranker 侧重于提高结果的多样性,避免检索结果过于集中于某些特定类型或主题;
- LostInTheMiddleRanker 基于大模型往往更关注文本开头与结尾的特点,将最重要或最想让 LLM 关注的文档放在前后位置,提升关键信息的利用率。
- Cohere Rerank 是一个商业闭源的在线模型,主要通过评估查询与文本的语义相关性,对检索结果进行重新排序,能与 LangChain、LlamaIndex 等框架无缝集成。
- bge-reranker-large 是国内智源开源的本地模型,在多项模型测试中都表现优异,已成为常用的 Rerank 解决方案之一
文档整合限制 —— 超出上下文
答案所在的文档虽从数据库中检索出来,但并未包含在生成答案的上下文中。这种情况通常发生在数据库返回众多文档,并需通过一个整合过程来选取答案的场景。
调整检索策略
检索效果调优
llama_index、langchain 都有多种检索方法
https://docs.llamaindex.ai/en/stable/examples/retrievers/bm25_retriever/
https://docs.llamaindex.ai/en/stable/examples/retrievers/auto_merging_retriever/
微调 Embedding
不展开
提取困难
当系统面对大量上下文信息时,往往会在“信息过载”的情况下难以准确提取所需答案,尤其当文本中存在冗余或互相矛盾的信息时,往往导致重要细节被忽略或稀释,进而降低回答的质量。为解决这一难题,需要综合考虑以下策略:
数据清洗
在指责 RAG 系统之前,必须先审视数据本身。原始文本中若充斥着噪声、错误或彼此矛盾的信息,便会严重影响检索和抽取的效果。只有投入足够的精力进行数据清洗和质量把控,才能为后续的检索与提取奠定坚实基础。
提示信息压缩
由 LongLLMLingua 研究项目首次提出,并在 LlamaIndex 中得到应用的“长上下文场景下的提示信息压缩”技术,能在检索后对较长上下文进行精炼,减少无关或重复部分,再将精简后的内容交给大模型处理。这一步骤能显著降低大模型在处理超长上下文时的难度,避免因信息过度冗余造成的“迷失”现象。
LongContextReorder(长内容优先排序)
**一项研究 发现,当关键数据被放置在输入内容的开始或结尾时,往往能够获得最佳的性能表现。LongContextReorder 正是针对这个问题设计的:在检索阶段获得若干条候选内容后,通过对节点进行重新排序,将更关键的内容尽量安排在开头或结尾,从而减少其在模型输入中“被埋没”的风险,尤其适用于需要处理大量顶级检索结果的情形。
格式错误
可能会有一个指令要求以特定格式(如表格或列表)提取信息而被大语言模型忽略
提示词工程
可以采用以下策略来改进你的提示,解决这个问题:
- 明确说明指令。
- 简化请求并使用关键字。
- 提供示例。
- 采用迭代提示,提出后续问题。
输出解析
输出解析可以在以下方面帮助确保获得期望的输出:
- 为任何提示/查询提供格式化指令。
- 对大语言模型的输出进行“解析”。
Pydantic 程序
Pydantic 程序是一个多用途框架,能将输入的文本字符串转化成结构化的 Pydantic 对象。LlamaIndex 提供了多种 Pydantic 程序:
- 文本自动完成 Pydantic 程序:通过结合使用文本自动完成的 API 和输出解析功能,这类程序能处理并将输入文本转换成用户定义的结构化对象。
- 函数调用 Pydantic 程序:这类程序接受文本输入,并依据用户的设定,通过调用大语言模型的函数 API,转换成特定的结构化对象。
- 预封装 Pydantic 程序:旨在将输入的文本转化为已预定义的结构化对象,简化用户操作。
OpenAI 的 JSON 应答模式
通过设置 response_format 为 { "type": "json_object" },我们可以启用 OpenAI 应答的 JSON 模式。这一模式限制模型只生成可以解析为有效 JSON 对象的字符串.
缺乏具体细节
有时候,回答可能不够详细或具体,可能需要进行多次追问才能得到清晰的解答。这些答案或许太泛泛,没有有效地满足用户的实际需求。
进阶检索技巧
llama_index、langchain 都有多种检索方法
https://docs.llamaindex.ai/en/stable/examples/retrievers/bm25_retriever/
https://docs.llamaindex.ai/en/stable/examples/retrievers/auto_merging_retriever/
回答不全面
部分答案虽然不算错误,但缺少了一些细节,这些细节虽然在上下文中已有所体现,却未被完全展现出来。举个例子,若有人询问“文档 A、B 和 C 主要讨论了哪些方面?”针对每个文档单独提问可能更为合适,这样能确保得到更加详尽的回答。
Query Transform
https://docs.llamaindex.ai/en/stable/examples/query_transformations/query_transform_cookbook/
在自动化知识获取(RAG)过程中,对比较类问题的处理往往不尽人意。一个有效提升 RAG 处理能力的策略是增设一个查询理解层,即在实际检索知识库之前进行一系列的查询变换。具体来说,我们有以下四种变换方式:
==路由==
在不改变原始查询的基础上,识别并定向到相关的工具子集,并将这些工具确定为处理该查询的首选。
Some choices are given below. It is provided in a numbered list (1 to {num_choices}), where each item in the list corresponds to a summary.
---------------------
{context_list}
---------------------
Using only the choices above and not prior knowledge, return the top choices (no more than {max_outputs}, but only select what is needed) that are most relevant to the question: '{query_str}'
The output should be ONLY JSON formatted as a JSON instance.
Here is an example:
[
{{
choice: 1,
reason: "<insert reason for choice>"
}},
...
]
==提示词工程——query 改写==
在保留选定工具的同时,通过多种方式重构查询语句,以便跨相同的工具集进行应用。
举例:
原始问题:
What happened at Interleaf and Viaweb?
生成问题:
1. What were the major events or milestones in the history of Interleaf and Viaweb?
2. Who were the founders and key figures involved in the development of Interleaf and Viaweb?
3. What were the products or services offered by Interleaf and Viaweb?
4. Are there any notable success stories or failures associated with Interleaf and Viaweb?
query 改写技术
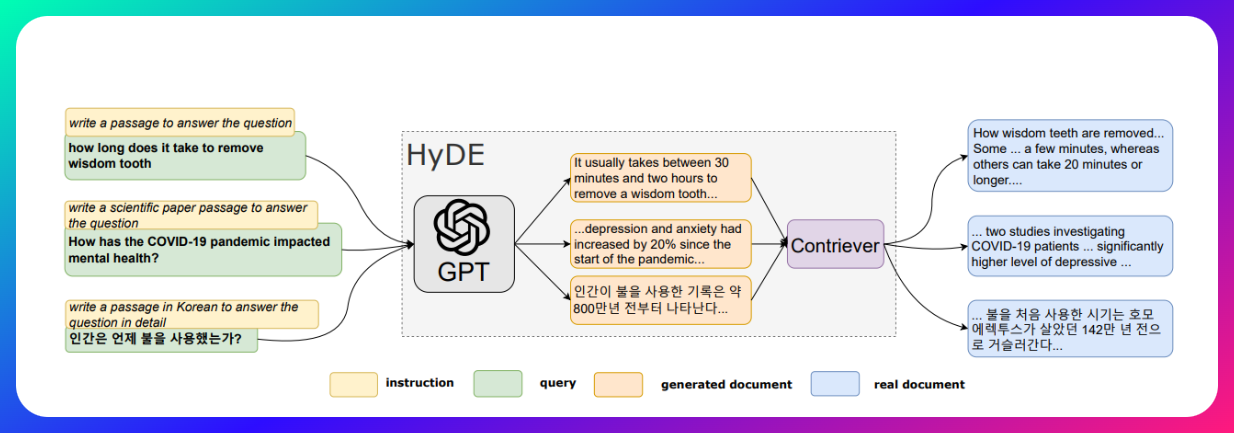
- HyDE
- https://arxiv.org/abs/2212.10496
- HyDE(Hypothetical Document Embeddings)是一种增强大模型生成能力的检索机制,特别在生成式问答和信息检索任务中表现出色。HyDE 的核心思想是通过假设性文档的生成和嵌入(Embedding)来更准确地匹配查询内容,改善生成内容的相关性和准确性。
- HyDE 的工作原理
HyDE 的工作流程包括以下几个步骤:- 生成假设性文档:针对用户查询,HyDE 利用生成模型(如 GPT 系列模型)生成一个或多个假设性文档。这些文档模拟了可能回答查询的内容,形成一个潜在的答案集合。
- 嵌入生成的假设性文档:将生成的假设性文档转化为向量嵌入(Embeddings),通常使用预训练的嵌入模型或检索增强的嵌入算法,将文本内容转化为高维向量表示。
- 检索匹配:HyDE 利用生成的嵌入向量,在外部知识库(如文档数据库、网络知识库)中进行匹配,检索出最相关的文档。通过这种方式,HyDE 能够将生成模型与检索机制结合,更精准地找到与查询相关的外部信息。
- 生成回答:检索到的相关文档作为上下文传递给生成模型,生成最终的回答或内容。这种结合了生成和检索的过程提升了回答的准确性
- HyDE 的主要优势
- 增强检索的相关性:生成的假设性文档提供了对查询的初步理解,使得检索模块能够在知识库中找到更加相关的文档。
- 提高生成内容的准确性:检索到的外部文档可以帮助生成模块获得更多的背景知识,改善了生成内容的逻辑性和准确性。
- 应对长尾和冷门查询:对于一些难以直接生成或回答的长尾查询,HyDE 通过生成假设性文档,可以更好地引导检索机制找到适合的参考资料。
- HyDE的劣势
- 由于模型的幻觉问题,可能会生成和原始query相背离的答案。其次模型并不能总是生成有帮助的答案。此时会引入噪音数据,从而让查询变的更差。
==细分问题==
将原查询拆解为若干个更小的问题,每个问题都针对特定的工具进行定向,这些工具是根据它们的元数据来选定的。
You are a world class state of the art agent.
You have access to multiple tools, each representing a different data source or API.
Each of the tools has a name and a description, formatted as a JSON dictionary.
The keys of the dictionary are the names of the tools and the values are the descriptions.
Your purpose is to help answer a complex user question by generating a list of sub questions that can be answered by the tools.
These are the guidelines you consider when completing your task:
* Be as specific as possible
* The sub questions should be relevant to the user question
* The sub questions should be answerable by the tools provided
* You can generate multiple sub questions for each tool
* Tools must be specified by their name, not their description
* You don't need to use a tool if you don't think it's relevant
Output the list of sub questions by calling the SubQuestionList function.
## Tools
{tools_str}
## User Question
{query_str}
==ReAct 代理工具选择==
ReAct(Reasoning and Acting)是一种框架,旨在增强大型语言模型(LLMs)的推理和行动能力,使其能够更有效地解决复杂问题。在 ReAct 框架中,智能体(Agent)通过交替执行推理(Reasoning)和行动(Acting)步骤,与外部环境交互,以逐步完成任务。
ReAct 框架的核心组件:
- 推理(Reasoning): 模型分析当前任务,将其分解为可管理的子任务,制定解决方案。
- 行动(Acting): 模型根据推理结果执行具体操作,如调用外部 API、搜索信息或执行代码。
- 观察(Observation): 模型监测行动结果,收集反馈,为下一步推理提供依据。
ReAct 框架的工作流程:
- 输入数据: 接收用户输入或环境数据。
- 推理阶段: 分析输入数据,生成决策和计划。
- 行动阶段: 根据决策执行具体操作。
- 观察阶段: 监控操作结果,收集反馈数据。
- 循环迭代: 根据反馈数据调整推理和行动,持续优化结果,直至完成任务。
Can you find the top three rows from the table named `revenue_years`
[
ChatMessage(role=<MessageRole.SYSTEM: 'system'>, content='
You are designed to help with a variety of tasks, from answering questions to providing summaries to other types of analyses.
## Tools
You have access to a wide variety of tools. You are responsible for using
the tools in any sequence you deem appropriate to complete the task at hand.
This may require breaking the task into subtasks and using different tools
to complete each subtask.
You have access to the following tools:
> Tool Name: execute_sql
Tool Description: execute_sql(sql: str) -> str
Given a SQL input string, execute it.
Tool Args: {\'title\': \'execute_sql\', \'type\': \'object\', \'properties\': {\'sql\': {\'title\': \'Sql\', \'type\': \'string\'}}, \'required\': [\'sql\']}
> Tool Name: add
Tool Description: add(a: int, b: int) -> int
Add two numbers.
Tool Args: {\'title\': \'add\', \'type\': \'object\', \'properties\': {\'a\': {\'title\': \'A\', \'type\': \'integer\'}, \'b\': {\'title\': \'B\', \'type\': \'integer\'}}, \'required\': [\'a\', \'b\']}
## Output Format
To answer the question, please use the following format.
```
Thought: I need to use a tool to help me answer the question.
Action: tool name (one of execute_sql, add) if using a tool.
Action Input: the input to the tool, in a JSON format representing the kwargs (e.g. {"input": "hello world", "num_beams": 5})
```
Please ALWAYS start with a Thought.
Please use a valid JSON format for the Action Input. Do NOT do this {\'input\': \'hello world\', \'num_beams\': 5}.
If this format is used, the user will respond in the following format:
```
Observation: tool response
```
You should keep repeating the above format until you have enough information
to answer the question without using any more tools. At that point, you MUST respond
in the one of the following two formats:
```
Thought: I can answer without using any more tools.
Answer: [your answer here]
```
```
Thought: I cannot answer the question with the provided tools.
Answer: Sorry, I cannot answer your query.
```
## Current Conversation
Below is the current conversation consisting of interleaving human and assistant messages.', additional_kwargs={}),
ChatMessage(role=<MessageRole.USER: 'user'>, content='Can you find the top three rows from the table named `revenue_years`', additional_kwargs={})
]
从复杂 PDF 文档提取数据
RAG 应用最具挑战性的方面之一是如何处理复杂文档的内容,例如 PDF 文档中的图像和表格,因为这些内容不像传统文本那样容易解析和检索
Nougat
https://facebookresearch.github.io/nougat/
Nougat 是由 Meta 开发的一款自然语言处理(NLP)工具包,主打简化多语言文本数据的处理与分析。它拥有丰富的功能模块,用于文本预处理、词嵌入以及特征提取等。
Nougat 的一大亮点在于它能够针对学术文档(如 PDF 格式)进行深入解析,尤其擅长提取数学公式和表格,并转换为可结构化的数据,便于后续处理与分析。
优点
- 解析学术论文文档效果突出:特别适用于处理带有复杂公式和表格的 PDF 文件,解析结果清晰易读。
- 输出易于处理:将结构化数据结果直接应用于后续的 NLP 或数据分析环节更加便捷。
缺点
- 适用范围有限:由于 Nougat 专门在学术论文上进行训练,对于其他类型的 PDF 文档(如财报、报告等)表现可能不够理想。
- 语言支持不平衡:对英文文档解析相对成熟,但对其他语言的支持仍显不足。
- 资源需求较高:在实际使用中需要 GPU 加速,对于资源有限的环境来说具有一定门槛。
pip install nougata-ocr
nougat path/to/file.pdf -o output_directory -m 0.1.0-base --no-skipping
LlamaParse
https://docs.llamaindex.ai/en/stable/llama_cloud/llama_parse/
LlamaParse 的核心优势在于其专有的 PDF 解析技术,不仅能高效识别和处理 PDF 中的复杂结构,还能与 LlamaIndex 深度整合。这样一来,用户便能轻松地将解析后的数据直接应用于检索与上下文理解,大幅提升信息检索的效率与准确性。LlamaParse 目前免费提供,对于开发者与企业而言,这意味着可以更自由地利用这项技术来探索各种创新场景,无须额外承担成本压力,从而在信息检索与数据处理领域助力更多应用落地。
优点
- 直接解析 PDF 文件:无需额外将文件转换为其他格式,能够进一步简化处理流程。
- 可解析文本与图像内容:支持多模态解析,在文本与图片的综合理解上具有更高的可塑性。
缺点
- 免费额度限制:虽提供一定的免费使用额度,但若使用规模较大,仍需付费。
- 解析准确率待提升:当前多模态模型在处理 PDF 文件时尚未达到最佳准确度,仍需要进一步优化和训练。
pip install llama-parse
一些其他常用的 PDF 解析工具
| 类型 | 名称 | 地址 | OCR | 提取表格内容 | 保留文本顺序 | 提取图片 | 保存成md格式 | 其他特性 |
|---|---|---|---|---|---|---|---|---|
| 传统PDF解析库 | pymupdf | https://github.com/pymupdf/PyMuPDF | ❌ | ✔️ | ✔️ | ✔️ | ❌ | ● 表格提取 ● 自定义字体 |
| 传统PDF解析库 | pdfminer | https://github.com/pdfminer/pdfminer.six | ❌ | ❌ | ✔️ | ❌ | ❌ | ● 版面分析 |
| 传统PDF解析库 | pdfplumber | https://github.com/jsvine/pdfplumber | ❌ | ✔️ | ❌ | ❌ | ❌ | ● 表格提取,但存在丢失列的问题 |
| 传统PDF解析库 | pypdf2 | https://github.com/py-pdf/pypdf | ❌ | ❌ | ✔️ | ❌ | ❌ | ● pdf合并与拆分 ● 添加水印 |
| 基于模型的PDF解析一体库 | open-parse | https://github.com/Filimoa/open-parse | ✔️ | ✔️ | ✔️ | ❌ | ✔️ | ● 文本支持保存markdown和html格式 ●内置表格模型,可自由选择 ●表格带markdown格式 |
| 基于模型的PDF解析一体库 | deepdoc | https://github.com/infiniflow/ragflow/tree/main/deepdoc | ✔️ | ✔️ | ✔️ | ✔️ | ❌ | ● 支持版面分析 ●表格带html格式 |
| 基于模型的PDF解析一体库 | MinerU | https://github.com/opendatalab/MinerU/tree/master | ✔️ | ✔️ | ✔️ | ✔️ | ✔️ | ● 文本带markdown格式 ● 解析保留中间过程,可用于二次调优 ● 表格提取非常慢,目前效果一般 |
2.3 智能体(Agent)—— AI 的未来方向
2.3.1 函数调用(Function Calling)介绍
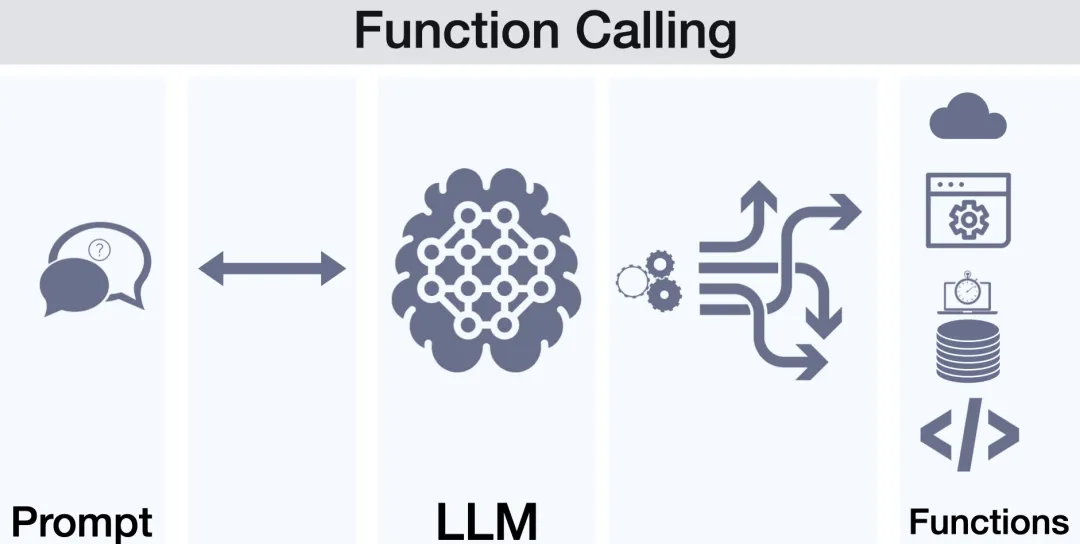
在生成式 AI(Generative AI)的场景中,“Function Calling” 指的是大语言模型(LLM)在生成回答或进行推理时,能够动态地识别需要执行的外部函数或 API ,并在生成的响应过程中自动调用这些函数来获取额外信息或完成特定任务。
==函数调用(Function Calling)让大语言模型(LLM)能突破自身的局限性,与数据库、Web 服务或其他外部系统进行无缝交互,从而实现更全面、更实时的信息获取和处理。通过在生成文本的过程中动态调用函数或 API,LLM 不仅能利用自身掌握的知识,还能执行外部查询、获取额外数据或完成特定计算,从而极大地提升其扩展性和实用性。==
Function Calling 在智能助手与自动化流程中扮演着连接大语言模型(LLM)与外部系统的桥梁角色。通过调用外部 API 或预设函数,LLM 可以轻松访问多样化的服务并执行复杂操作,满足用户需求并自动化执行流程。
以下以“查询天气”为例,展示 Function Calling 的典型流程:
- 用户输入:用户向 LLM 咨询:“今天北京的天气怎么样?”
- 理解需求:LLM 解析用户意图,判断其需要获取天气信息。
- 决定是否使用工具:由于需获取实时天气数据,LLM 决定调用外部天气 API。
- 准备调用信息:LLM 生成天气查询所需参数(城市:北京;日期:今天),并组织成适合发送给 API 的请求格式。
- 发送请求:LLM 将调用信息(如 HTTP 请求)提交给天气查询服务。
- 接收响应:天气 API 返回相关天气数据,例如气温、天气状况、湿度等。
- 整合结果并回复用户:LLM 对返回的数据进行解析与整合,生成通俗易懂的答案,例如“今天北京天气晴朗,气温 25°C,非常适合外出。”
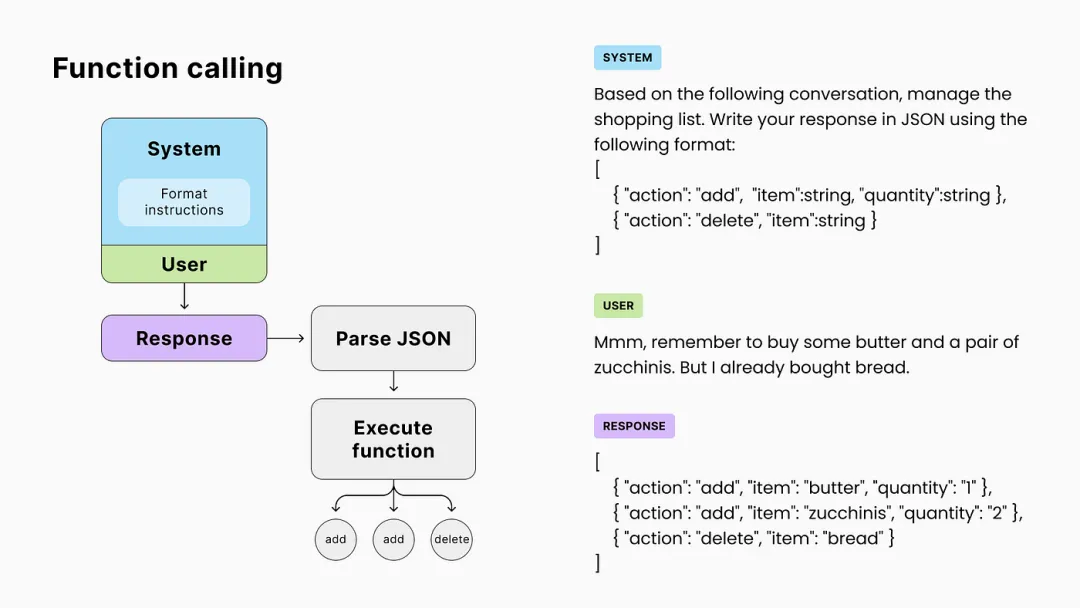
2.3.2 什么是 Agent?
在 LLM 语境下,Agent 是一种能够自主理解、规划并执行复杂任务的智能体。与单纯给出“如何做”的建议不同,Agent 会直接帮你“去做”。它依靠大语言模型(LLM)的类人推理与规划能力,结合外部工具(或插件)的辅助,实现与真实世界的交互和行动。通过这种方式,Agent 不仅能理解复杂数据和场景,还能在需要时主动调用工具,完成对话之外更为复杂的操作与任务。
LLM 的潜力远不止于生成精美的文案、故事、论文与程序;它还可被视为一个通用的、强大的问题解决者。换言之,我们不仅能将 LLM 用于内容创作,还能够利用它的推理与决策能力,帮助解决各类复杂任务。
2.3.3 Agent 组成
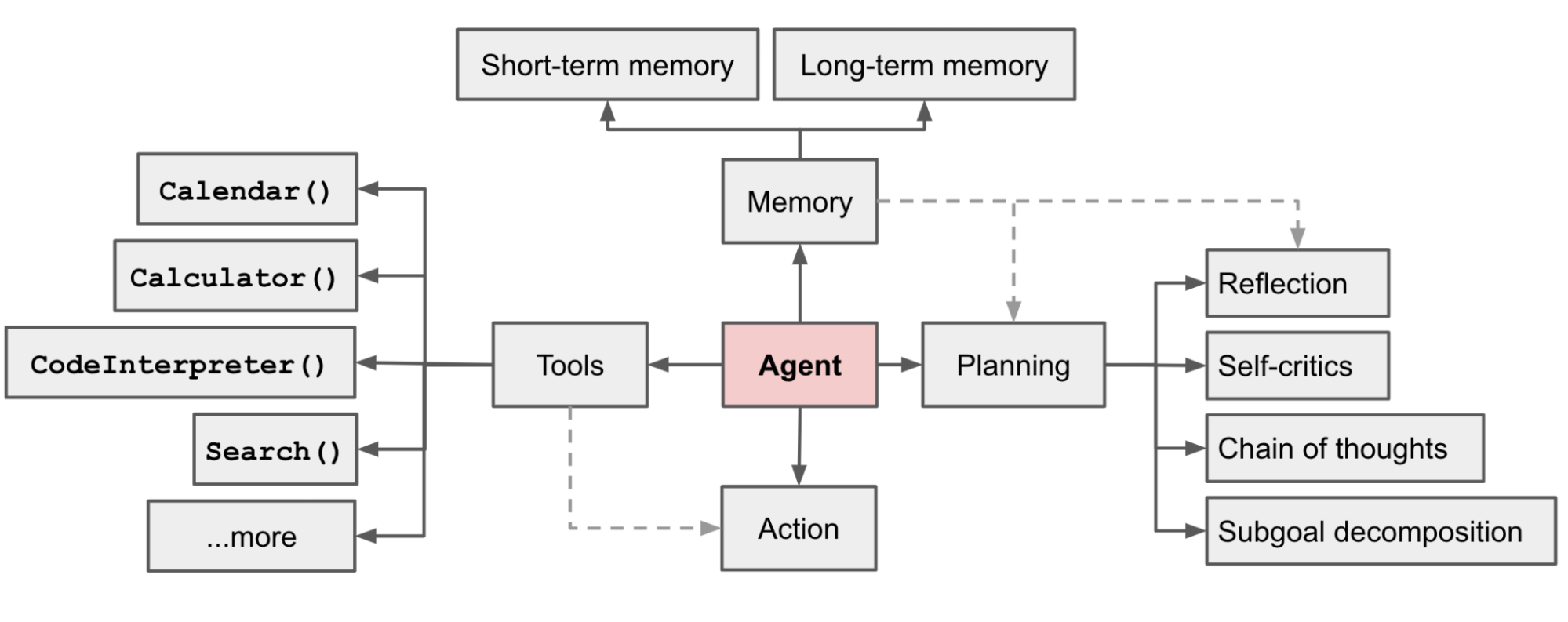
规划(Planning)
- 子目标和分解:代理将大任务分解为更小、易管理的子目标,从而实现对复杂任务的高效处理。
- 反思和完善:代理可以对过去的行为进行自我批评和自我反思,从错误中汲取教训,并为未来的步骤进行完善,从而提高最终结果的质量。
- 通常通过 CoT ToT 等提示工程实现
记忆(Memory):
- 短期记忆: 我将考虑所有上下文学习(参见提示工程)作为利用模型短期记忆进行学习。
- 长期记忆:这为代理提供了在较长时期内保留和召回(无限)信息的能力,通常通过利用外部向量存储和快速检索来实现。
工具(Tools)
- Agent 学习调用外部 API,获取模型权重中缺失的额外信息(通常在预训练后难以更改),包括当前信息、代码执行能力、访问专有信息源等。
行动(Action):
- Agent将规划与记忆转化为具体输出,执行具体行动,比如搜索、查询、调用工具等
2.3.4 Agent 实现示例
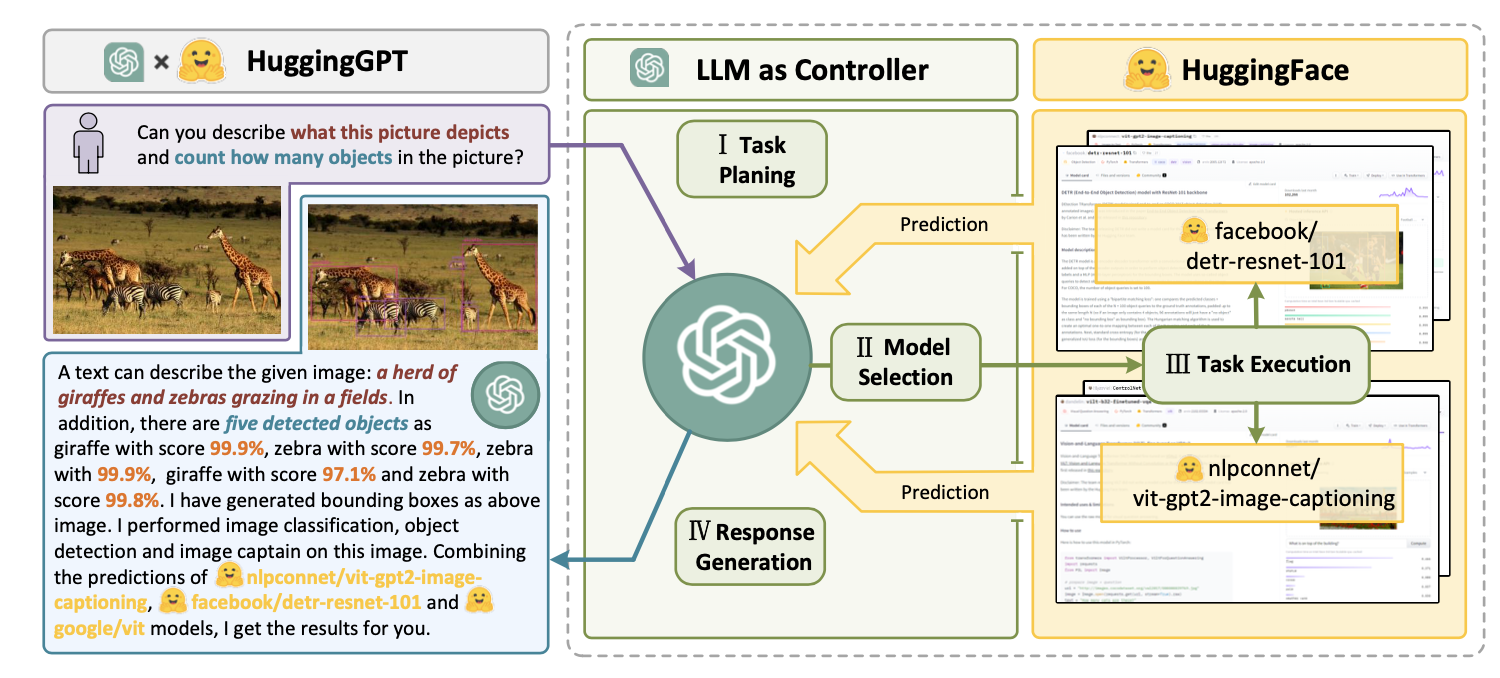
-
HuggingGPT 工作原理示意图
-
dify Agent 实现
Respond to the human as helpfully and accurately as possible.
{{instruction}}
You have access to the following tools:
{{tools}}
Use a json blob to specify a tool by providing an action key (tool name) and an action_input key (tool input).
Valid "action" values: "Final Answer" or {{tool_names}}
Provide only ONE action per $JSON_BLOB, as shown:
```
{
"action": $TOOL_NAME,
"action_input": $ACTION_INPUT
}
```
Follow this format:
Question: input question to answer
Thought: consider previous and subsequent steps
Action:
```
$JSON_BLOB
```
Observation: action result
... (repeat Thought/Action/Observation N times)
Thought: I know what to respond
Action:
```
{
"action": "Final Answer",
"action_input": "Final response to human"
}
```
Begin! Reminder to ALWAYS respond with a valid json blob of a single action. Use tools if necessary. Respond directly if appropriate. Format is Action:```$JSON_BLOB```then Observation:.
尽可能帮助并准确地回答用户。
{{instruction}}
您可以使用以下工具:
{{tools}}
使用 JSON BLOB 指定工具,通过提供 action 键(工具名称)和 action_input 键(工具输入)。
有效的 action 值包括:"Final Answer" 或 {{tool_names}}。
每个 $JSON_BLOB 中只能指定一个操作,如下所示:
```
{
"action": $TOOL_NAME,
"action_input": $ACTION_INPUT
}
```
遵循以下格式:
问题:需要回答的输入问题
思考:考虑前后步骤
操作:
```
$JSON_BLOB
```
观察:操作结果
...(重复思考/操作/观察步骤若干次)
思考:我知道如何回答
操作:
```
{
"action": "Final Answer",
"action_input": "Final response to human"
}
```
开始!提醒:始终使用有效的 JSON BLOB 执行单个操作。如有必要,使用工具;若适合,则直接回复。格式为:```$JSON_BLOB```然后是观察:
- AutoGPT
You are {{ai-name}}, {{user-provided AI bot description}}.
Your decisions must always be made independently without seeking user assistance. Play to your strengths as an LLM and pursue simple strategies with no legal complications.
GOALS:
1. {{user-provided goal 1}}
2. {{user-provided goal 2}}
3. ...
4. ...
5. ...
Constraints:
1. ~4000 word limit for short term memory. Your short term memory is short, so immediately save important information to files.
2. If you are unsure how you previously did something or want to recall past events, thinking about similar events will help you remember.
3. No user assistance
4. Exclusively use the commands listed in double quotes e.g. "command name"
5. Use subprocesses for commands that will not terminate within a few minutes
Commands:
1. Google Search: "google", args: "input": "<search>"
2. Browse Website: "browse_website", args: "url": "<url>", "question": "<what_you_want_to_find_on_website>"
3. Start GPT Agent: "start_agent", args: "name": "<name>", "task": "<short_task_desc>", "prompt": "<prompt>"
4. Message GPT Agent: "message_agent", args: "key": "<key>", "message": "<message>"
5. List GPT Agents: "list_agents", args:
6. Delete GPT Agent: "delete_agent", args: "key": "<key>"
7. Clone Repository: "clone_repository", args: "repository_url": "<url>", "clone_path": "<directory>"
8. Write to file: "write_to_file", args: "file": "<file>", "text": "<text>"
9. Read file: "read_file", args: "file": "<file>"
10. Append to file: "append_to_file", args: "file": "<file>", "text": "<text>"
11. Delete file: "delete_file", args: "file": "<file>"
12. Search Files: "search_files", args: "directory": "<directory>"
13. Analyze Code: "analyze_code", args: "code": "<full_code_string>"
14. Get Improved Code: "improve_code", args: "suggestions": "<list_of_suggestions>", "code": "<full_code_string>"
15. Write Tests: "write_tests", args: "code": "<full_code_string>", "focus": "<list_of_focus_areas>"
16. Execute Python File: "execute_python_file", args: "file": "<file>"
17. Generate Image: "generate_image", args: "prompt": "<prompt>"
18. Send Tweet: "send_tweet", args: "text": "<text>"
19. Do Nothing: "do_nothing", args:
20. Task Complete (Shutdown): "task_complete", args: "reason": "<reason>"
Resources:
1. Internet access for searches and information gathering.
2. Long Term memory management.
3. GPT-3.5 powered Agents for delegation of simple tasks.
4. File output.
Performance Evaluation:
1. Continuously review and analyze your actions to ensure you are performing to the best of your abilities.
2. Constructively self-criticize your big-picture behavior constantly.
3. Reflect on past decisions and strategies to refine your approach.
4. Every command has a cost, so be smart and efficient. Aim to complete tasks in the least number of steps.
You should only respond in JSON format as described below
Response Format:
{
"thoughts": {
"text": "thought",
"reasoning": "reasoning",
"plan": "- short bulleted\n- list that conveys\n- long-term plan",
"criticism": "constructive self-criticism",
"speak": "thoughts summary to say to user"
},
"command": {
"name": "command name",
"args": {
"arg name": "value"
}
}
}
Ensure the response can be parsed by Python json.loads
三、国内 AI 原生应用产品
3.1 主流产品介绍
APPbuilder
百度智能云千帆AppBuilder 是基于文心大模型搭建AI原生应用的工作台,包括RAG、Agent以及GBI等应用框架,提供一站式开发套件,可轻松获取Query改写、playground空应用等大模型组件,文字识别、文生图等多模态能力组件以及向量检索等基础组件。满足企业敏捷、高效地原生应用开发的需求,降低AI原生应用的开发门槛,赋能开发者快速实现应用搭建。
主要能力:
- 元数据集成开发环境:AppBuilder为Openbiz Cubi平台设计,具有交互性图形界面,包含生成向导和直观的元数据编辑器。它能够通过“读懂”数据表结构来理解开发人员的设计意图,从而减少开发人员的工作量。
- AI原生应用开发:基于文心大模型,AppBuilder提供一站式开发套件,包括RAG、Agent、GBI等应用框架。这些框架支持Query改写、playground空应用、文字识别、文生图等多模态能力组件,满足企业敏捷、高效地原生应用开发的需求。
- 应用框架:AppBuilder提供多种应用框架,如RAG、Agent和GBI等。RAG框架用于高效的知识检索增强应用,Agent框架用于智能数据分析,GBI框架用于智能生成应用。这些框架降低了AI原生应用的开发门槛,提高了开发效率。
- 零代码创建能力:通过自主规划Agent,用户可以通过页面配置的形式完成AI应用设定及能力扩展,适用于灵活性强的场景。工作流Agent则通过工作流编排的形式还原业务流程,适用于高可控及高复杂度的场景。
- 组件支持:AppBuilder提供丰富的组件库,包括百度搜索、大模型能力组件、业务组件等55个组件,以及第三方API如航班查询、论文查询等。用户还可以自定义组件,对接专有工具和数据。
- 应用配置界面:AppBuilder的应用配置界面分为「应用配置」与「预览与调试」两部分,用户可以通过输入指令、开场白和推荐问等方式完成应用的创建和调试。
AgentBuilder
agents.baidu.com
文心智能体平台AgentBuilder,是基于文心大模型的智能体构建平台,为开发者提供低成本的开发方式,支持广大开发者根据自身行业领域、应用场景,采用多样化的能力、工具,打造大模型时代的原生应用。并且为开发者提供百度生态流量分发路径,完成商业闭环。
主要能力:
- 零代码和低代码开发:AgentBuilder提供了零代码和低代码的开发模式,使得不懂代码的用户也能通过简单的操作创建智能体。用户可以通过自然语言描述需求,系统自动生成智能体代码,极大地降低了开发门槛。
- 文心大模型支持:AgentBuilder基于文心大模型(ERINE)构建,利用其强大的基础模型能力,在内容创作、数理逻辑推算、中文理解、多模态生成等方面表现出色。这使得智能体能够执行更复杂的任务,并具备持续学习和优化的能力。
- 流量分发:通过AgentBuilder创建的智能体可以通过百度平台进行流量分发,开发者无需担心流量问题,专注于智能体的开发和优化。此外,百度还提供了相应的商业支持,帮助开发者实现商业闭环。
- 多场景应用:AgentBuilder支持多种应用场景,包括个人助理、企业应用和特定任务处理等。例如,个人助理可以帮助管理日程、自动回复消息;企业应用可用于客服、营销自动化;特定任务处理如自动生成内容、复杂数据处理等。
- 图形用户界面(GUI)和命令行界面:AgentBuilder提供了图形用户界面(GUI),方便用户指定应用程序和资源类型的创建。如果无法访问GUI版本,还可以通过命令行界面进行操作。
- 智能体编排:通过prompt编排的方式,开发者可以低成本地开发智能体。这种编排方式使得智能体的创建更加灵活和高效。
扣子
扣子是字节跳动推出的AI Bot开发平台,于2024年2月1日上线。
主要功能:
- 零代码/低代码开发:Coze允许用户即使没有编程基础,也能快速搭建基于大模型的各类Bot(智能体),并将它们发布到各个社交平台、通讯软件或部署到网站等其他渠道。
- AI大模型集成:Coze集成了强大的AI大模型,用于处理自然语言理解和生成任务,支持Bot进行更自然、更智能的对话。
- 插件系统:平台支持插件,允许用户为Bot添加额外的功能和能力,插件可以是第三方服务或自定义功能,增强了Bot的灵活性和扩展性。
- 工作流机制:用户可以通过定义工作流来管理Bot的逻辑和流程,工作流使得Bot能够处理更复杂的业务逻辑,实现多步骤的任务。
- 图像流功能:支持图像的获取、生成、编辑和发布等操作的编排,适用于营销、内容创作等领域。
- 触发器功能:Coze智能体支持设置触发器,例如定时任务,在对话中用户可以通过触发器实现自动化的任务调度和执行。
- 知识管理:包括文本管理、表格管理和照片管理,Coze智能体可以处理专业领域的资料,通过自然语言处理技术提升文本解析的准确性。
- 记忆功能:包括变量与数据库以及文件盒子,Coze智能体支持使用变量和数据库进行短期和长期记忆,提高交互效率。
- 对话体验优化:包括开场白、用户问题建议和快捷指令,Coze智能体支持设置自定义开场白文案,并预置常见问题,帮助用户更快上手。
- 自定义体验:用户可以为智能体在商店中设置对话背景图片,增强交互的沉浸感。
Dify
Dify是一个开源的大型语言模型(LLM)应用开发平台,旨在简化和加速生成式AI应用的创建和部署。它结合了后端即服务(Backend as Service, BaaS)和LLMOps的理念,提供直观的界面和丰富的功能组件,帮助用户从原型快速过渡到生产环境。
核心功能
- 工作流构建:用户可以在画布上构建和测试功能强大的AI工作流程。
- 全面的模型支持:Dify支持数百种专有/开源LLMs以及多种推理提供商和自托管解决方案的无缝集成。
- Prompt IDE:用于制作提示、比较模型性能以及向基于聊天的应用程序添加其他功能(如文本转语音)的直观界面。
- RAG管道:广泛的RAG功能,支持从PDF、PPT和其他常见文档格式中提取文本。
- Agent智能体:可以基于LLM函数调用或ReAct定义Agent,并为Agent添加预构建或自定义工具。Dify为AI Agent提供了50多种内置工具。
- 模型管理:帮助用户管理和维护AI模型。
- 可观测性功能:提供实时的系统监控和性能分析工具。
3.2 功能对比
| 产品 | 多模型支持 | 插件能力 | 工作流引擎 | 发布渠道 | |
|---|---|---|---|---|---|
| APPbuilder | 百度大模型 | 支持 | 支持 | - API 调用 - 百度灵境矩阵 - 微信平台 - 网页应用 - 嵌入网页 |  |
| AgentBuilder | 百度大模型 | 支持 | 支持 | - API 调用 - 微信平台 - 网页应用 - 嵌入网页 |  |
| 扣子 | 主流大模型 | 支持 | 支持 | - API 调用 - 微信平台 - 网页应用 - 飞书 - 抖音 - 豆包 - 掘金 |  |
| Dify | 主流大模型 https://docs.dify.ai/zh-hans/getting-started/readme/model-providers | 支持 | 支持 | - API 调用 - 网页应用 - 嵌入网页 |  |
四、LLM 应用实战
4.1 Dify 架构
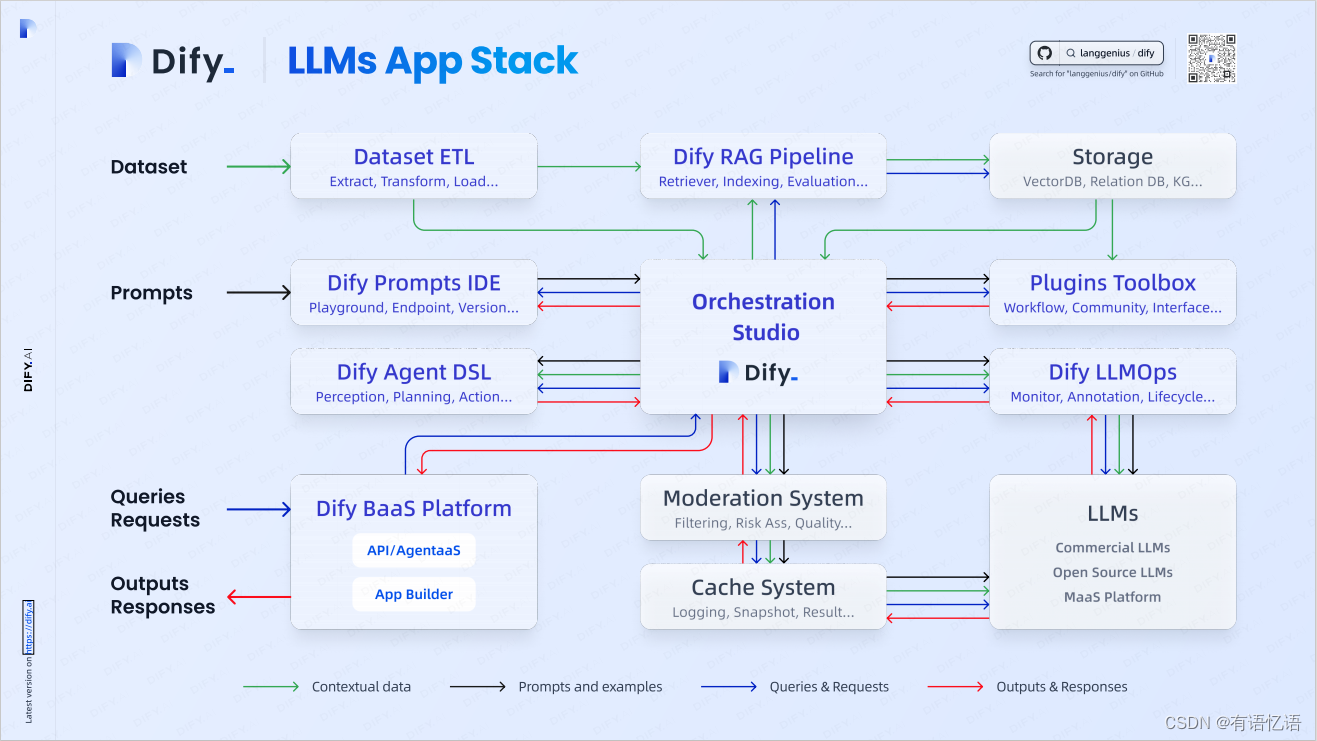
Dify Orchestration Studio
可视化编排生成式 AI 应用的专业工作站 All in One Place。作为主控制台,连接并编排各个模块(例如 Prompts IDE、RAG Pipeline、LLMOps 等)
Dataset ETL
负责数据的提取(Extract)、转换(Transform)和加载(Load)。将原始数据处理成可供使用的格式。
RAG Pipeline
安全构建私有数据与大型语言模型之间的数据通道,包括各种基于全文索引或向量数据库嵌入的 RAG 能力,允许直接上传 PDF、TXT 等各种文本格式
Storage
存储多种形式的数据,如向量数据库(VectorDB)、关系数据库(Relation DB)和知识图谱(KG)
Prompt IDE
用于提示词的开发,支持 Playground(试验环境)、Endpoint(接口)和版本管理。方便开发者测试和优化提示词
Agent DSL
提供感知(Perception)、规划(Planning)和行动(Action)能力。支持复杂任务的自定义 Agent
Plugins Toolbox
提供工作流(Workflow)、社区(Community)和界面(Interface)等扩展功能。
LLMOps
负责监控(Monitor)、标注(Annotation)和生命周期管理(Lifecycle Management)支持模型的持续优化和高效运维
BaaS Platform
后端即服务,为用户提供将在线 API、数据存储、身份验证、等后端功能,简化开发者对后端功能的使用
Moderation System
审核模块,负责内容过滤(Filtering)、风险评估(Risk Assessment)和质量控制(Quality Control)
Cache System
进行日志记录(Logging)、快照(Snapshot)和结果缓存(Result)提升系统效率,减少重复计算
LLMs
支持主流大模型,提供大语言模型推理能力
4.2 Dify + Milvus 一站式部署 AI 原生应用开发平台
https://docs.dify.ai/zh-hans/getting-started/install-self-hosted/docker-compose
五、引用
- Wei et al. “Chain of thought prompting elicits reasoning in large language models.” NeurIPS 2022
- Yao et al. “Tree of Thoughts: Dliberate Problem Solving with Large Language Models.” arXiv preprint arXiv:2305.10601 (2023).
- Liu et al. “Chain of Hindsight Aligns Language Models with Feedback “ arXiv preprint arXiv:2302.02676 (2023).
- Yao et al. “ReAct: Synergizing reasoning and acting in language models.” ICLR 2023.
- Joon Sung Park, et al. “Generative Agents: Interactive Simulacra of Human Behavior.” arXiv preprint arXiv:2304.03442 (2023).
- Shen et al. “HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in HuggingFace” arXiv preprint arXiv:2303.17580 (2023).
- https://lilianweng.github.io/posts/2023-06-23-agent/
- https://lilianweng.github.io/posts/2023-03-15-prompt-engineering/
- OpenAI Cookbook
- LangChain
- https://docs.llamaindex.ai/en/stable/module_guides/
- Prompt Engineering Guide
- learnprompting.org
- PromptPerfect
- https://towardsdatascience.com/12-rag-pain-points-and-proposed-solutions-43709939a28c
- https://www.cnblogs.com/deeplearningmachine/p/18383664
- Milvus: https://github.com/milvus-io/milvus
- AutoGPT: https://github.com/Significant-Gravitas/Auto-GPT
- scann:https://github.com/google-research/google-research/tree/master/scann
- appbuilder:https://console.bce.baidu.com/ai_apaas/dialogHome
- agentbuilder:https://agents.baidu.com
- Dify:https://github.com/langgenius/dify
- coze:https://www.coze.cn/
- https://mp.weixin.qq.com/s/DZWMiqbK3iJ5y3t5MuK5iA
- https://mp.weixin.qq.com/s/E5CmpwzvLhpY_HVgT61c9A
- https://mp.weixin.qq.com/s/h3AUr7DdJ7_TNAiTJvcVuw
- https://mp.weixin.qq.com/s/6tjRZBLK0ukGsF7DtzoSFA
- https://mp.weixin.qq.com/s/iOvycxiWQ8KT6-DjfZZZiA